
你可以说人类智能是大脑的模型“复杂”或“丰富”,但不能否认的是,其自由“切换”的效率(能力)也是如此惊人!很难想象未来AI不会向这个方向突破 — David 9
强化学习(RL)是一个有意思的存在,每一次算法 (AI)浪潮都可以让强化学习受益,但,每一次算法浪潮都不是因为强化学习的突破而产生。
我们以前聊过,如果世界上只有两种模型;“解释其他模型的模型”和“被其他模型解释的模型”,那么无疑,RL一直是后一种,甚至,大家没时间或没办法解释RL,因为大家都急着应用它做些什么。
回顾2020, RL依旧像个黑洞不断吸收着其他算法的养分,预计没有暂停的趋势,而人类生存的原始驱动就是各种“有形”或“无形”的reward(目标):
但RL要让计算机懂得“有形”或“无形”的目标并不容易,其令人诟病的学习效率问题david总结了下面几个:
1. 突破应用效率(开发效率)。
即使当RL算法开发完毕,在实际部署中依旧会有这样那样的问题。为了加速RL应用到真实世界,谷歌研究人员曾推出真实世界RL开发包。方便了RL开发中的系统延时,系统约束,系统扰动等的调试。
“系统延时”:现实中实时系统在做控制时,经常会有观测,回报的延时,
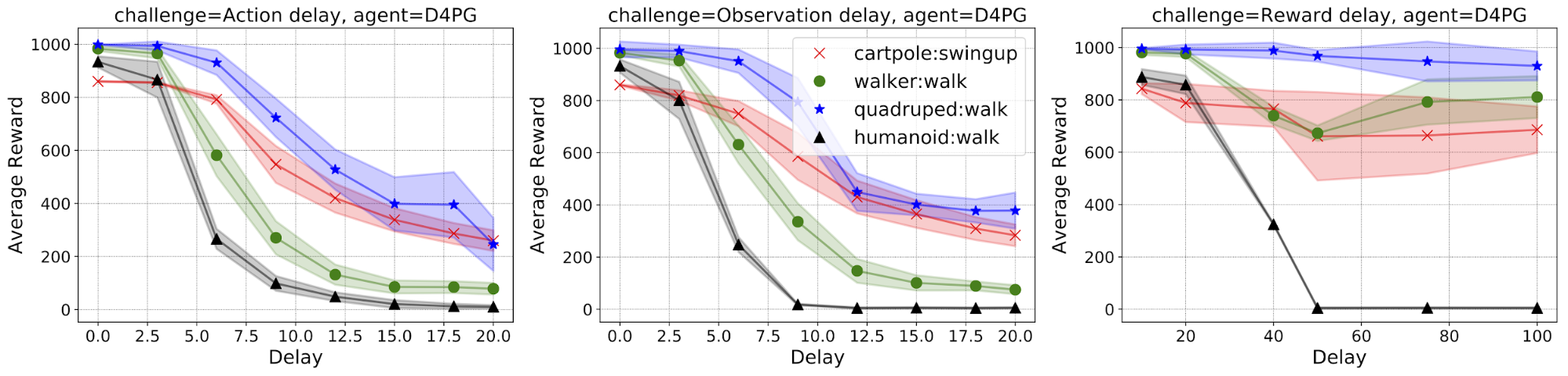
“系统约束”:超出范围的无效行为的约束,

“系统扰动”:对环境的扰动可以增强RL在真实世界的表现,

2. 突破数据效率(抽样效率)。
这一类的效率更多的是静态训练效率。agent学习体已经有了一些环境中的经验数据,如何高效地利用这些已有的数据加快RL训练?在这里会有很多有意思的创新。
其中一个是众所周知的“世界模型”(world model),具有代表性的是谷歌brain的DreamerV1(V2),通过抽象空间(“梦境”)的操作达到更好控制真实世界的目的:
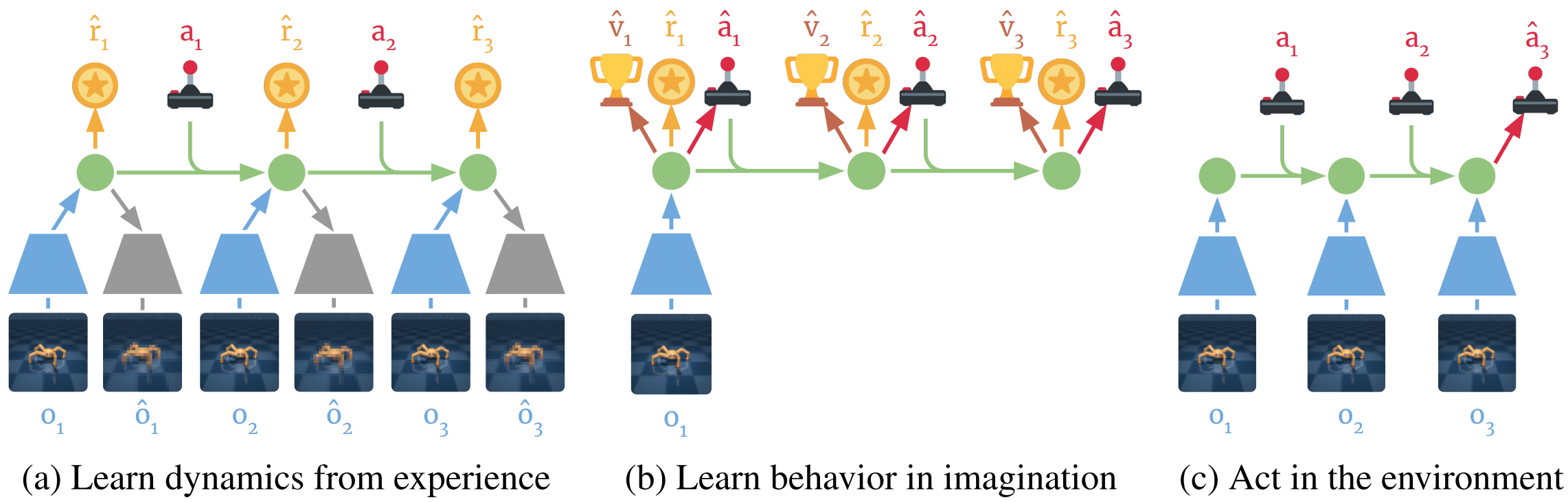
事实上,
