自我不是现成的,而是通过行动的选择不断生成的 —— 约翰 • 杜威
之前,我们已经通过心理学角度和认知系统2角度,探讨了意识及其产生。值得补充强调的是,意识不可能是孤岛,他是外部环境和内部大脑碰撞交互的结果,外部的环境和社会因素会深刻地影响大脑的运作,而大脑内部的解剖学结构和各个组织(特别是新皮质)的交互也起到至关重要的作用。
如果我们执意用白盒视角来探究大脑的意识,将是一条硬核的道路。但脑神经科学家倾向于选择这条道路,克里斯托夫·科赫就在《意识探秘》一书中阐述了他的探索道路,主要的研究内容就是揭示意识的神经相关集合NCC(neuronal correlates of consciousness)。通俗地说就是,足以引起特定有意识知觉的最小神经事件的集合。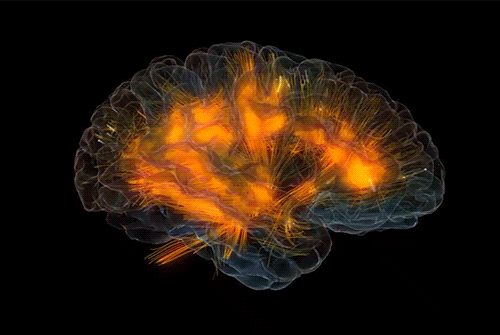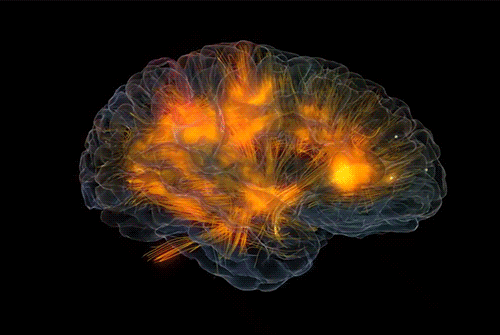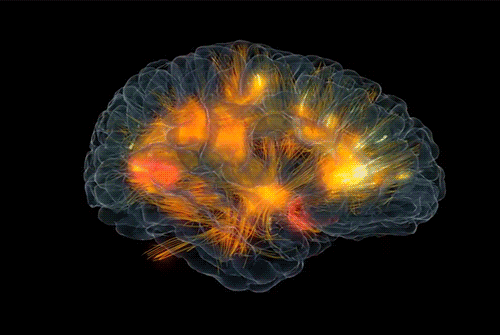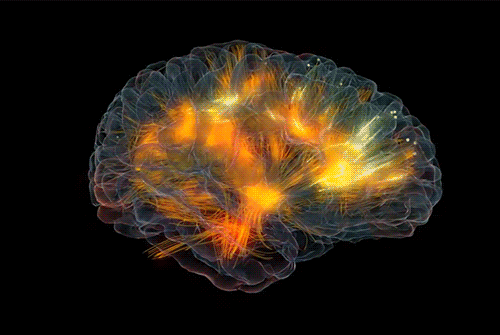 虽然这项任务看起来就很艰难,但是我们有信心假设,生物(特别是人类)产生意识是不需要所有的神经细胞参与的。尝试过冥想的人都保留着自我的意识,但隔绝了许多感官输入;沉浸工作的人,会有那么一秒,体验到自我的存在,但这个体验也似乎只限于体验,没有切实的感官输入或其他的明确目的;即使先天的盲人(没有视觉感官输入),也可以通过其他的感官(触觉,嗅觉),想象视觉的体验。
虽然这项任务看起来就很艰难,但是我们有信心假设,生物(特别是人类)产生意识是不需要所有的神经细胞参与的。尝试过冥想的人都保留着自我的意识,但隔绝了许多感官输入;沉浸工作的人,会有那么一秒,体验到自我的存在,但这个体验也似乎只限于体验,没有切实的感官输入或其他的明确目的;即使先天的盲人(没有视觉感官输入),也可以通过其他的感官(触觉,嗅觉),想象视觉的体验。 事实上科赫已经把初级视觉皮层(V1)排除在外了。
事实上科赫已经把初级视觉皮层(V1)排除在外了。
当然我认为需要强调的是,自我不是现成的,意识也不是现成的,而是通过行动的选择不断生成的,科赫的研究是在意识已经在那儿存在了的基础上的。我们人类在儿童阶段的意识和成人阶段的意识是一样的吗?两个阶段的NCC是一样的吗?我持怀疑态度。
当然,科赫的研究本身充满价值,其中许多新颖的观点和引人思考的实践,都值得我们长时间去探索,这里我总结几点重要的思考:
1. 我们是否应该放宽“意识”的定义?
在许多人狭隘的概念中,“意识”是要有“自我”的体验,已经为什么现在我们有这种“自我”的体验而不是其他的感受。但是,“自我”的概念真的这么重要吗?如果没有明确的“自我”概念,一个生物可以从第一人称视角感受,觉知,主观体验一些事物,这不可以被称为有意识吗?对于疼痛这种抽象概念,动物,婴儿虽然不能自身的体验,但是拥有了工作 记忆后,虽然可能无法用语言表达,但他们此刻能够切实地体验到甚至想象这种概念。 这些主观的体验在客观上是脑神经中优势NCC的发放。因此如果放宽“意识”的狭隘定义,就可以切实地做一些工作研究意识的基本组成。
这些主观的体验在客观上是脑神经中优势NCC的发放。因此如果放宽“意识”的狭隘定义,就可以切实地做一些工作研究意识的基本组成。
2. 既然僵尸行为这么有效,为什么还需要意识NCC?
对于有复杂性局部癫痫和梦游患者,甚至普通人的日常运动(骑车,钢琴),他们都可以完成自己熟悉的动作,这些自动行为或者条件反射只是执行某个内部程序,
这种刻板模式在很多情况下非常有效,但 继续阅读“现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论