目前习以为常的“验证集”和“测试集”的划分,在未来看来可能非常可笑 —— David 9
现今的机器学习(深度学习)的工作流已经到了需要重新思考的时候了。
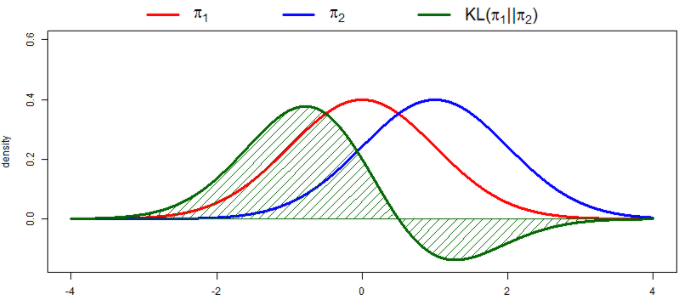
从最常见的“验证集”和“测试集”的划分,就已经很陈旧了(虽还不是一无是处)。 曾有学者认为,需要有一部分数据集彻底和训练集“隔绝”,从而达到最好的评估效果,即所谓的“测试集”,但其实漏洞很多,首先,用静态“测试集”去模拟动态的真实分布,在实际场景中会错误百出,其次,人类日常的学习没有什么“信息隔离”一说,接触到的信息都是可以学习的。有人会说,高考不就是人类通过“隔离”试卷信息选拔人才(“模型”)的过程吗?那么David要问一下大家,为什么会有“复读”再高考这种选择? 就是因为这个固定的隔离“测试集”漏洞太多了,有教师出题偏好的问题,有运气的问题,有学生状态的问题。
曾有学者认为,需要有一部分数据集彻底和训练集“隔绝”,从而达到最好的评估效果,即所谓的“测试集”,但其实漏洞很多,首先,用静态“测试集”去模拟动态的真实分布,在实际场景中会错误百出,其次,人类日常的学习没有什么“信息隔离”一说,接触到的信息都是可以学习的。有人会说,高考不就是人类通过“隔离”试卷信息选拔人才(“模型”)的过程吗?那么David要问一下大家,为什么会有“复读”再高考这种选择? 就是因为这个固定的隔离“测试集”漏洞太多了,有教师出题偏好的问题,有运气的问题,有学生状态的问题。
再说“验证集”,验证集和训练集真的区分很重要吗?人类日常生活往往是不区分训练和验证,有时一个样本在训练集里,有时该样本又在验证集,轮换验证和抽象,这一点,机器真的无法学会吗?
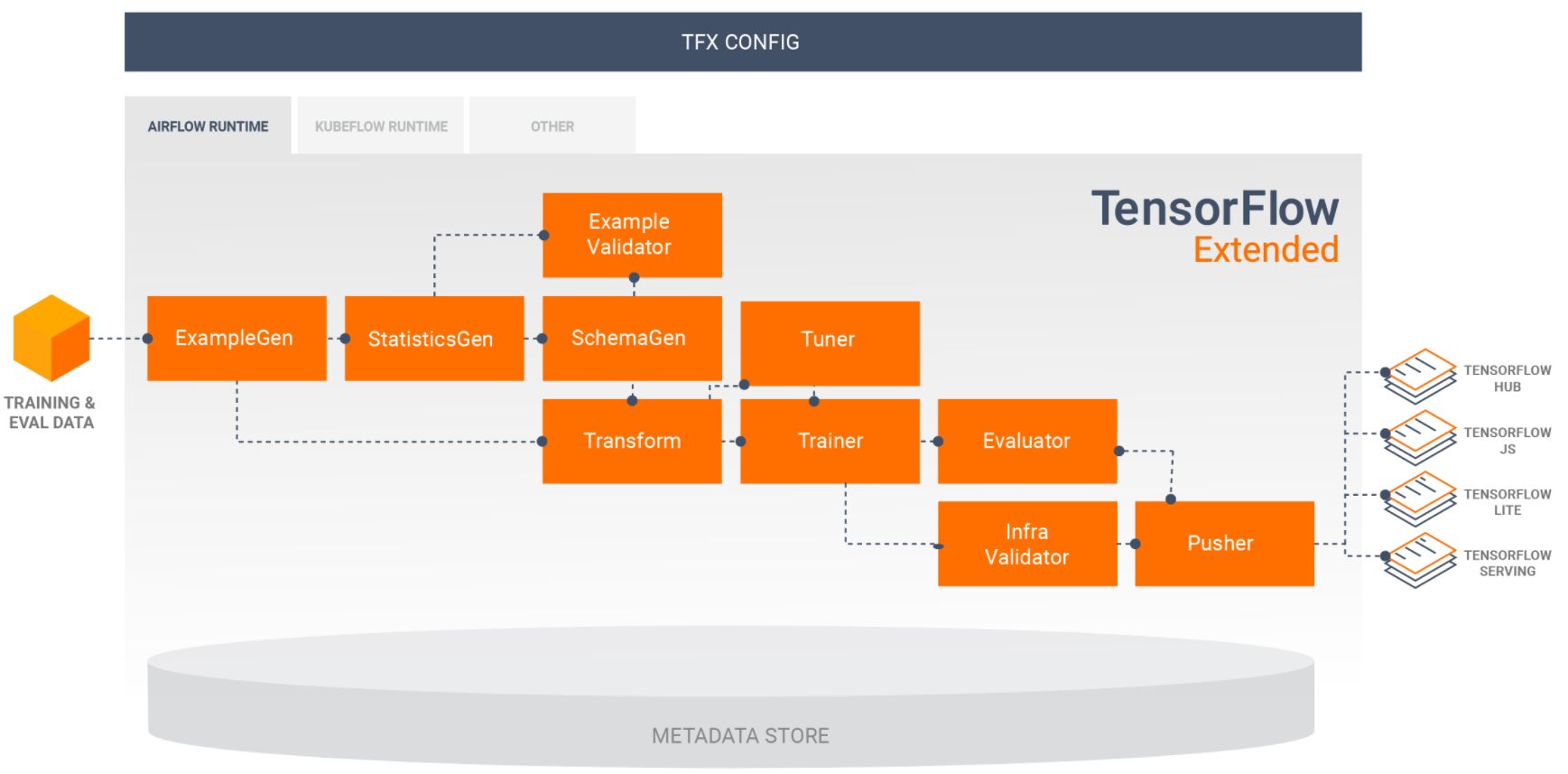
验证集和测试集应该是灵活的,很多人已经看到这一点,在模型部署阶段就应该有所考虑,TensorFlow的Extended (TFX)组件和Uber的可扩展ML服务框架,都曾有所尝试,但主要还是训练流程的优化和清洗。
这种“敏捷学习”固然重要,但在david看来,“怀疑训练”更重要。‘’怀疑”不仅仅局限于上述的验证集或测试集,
