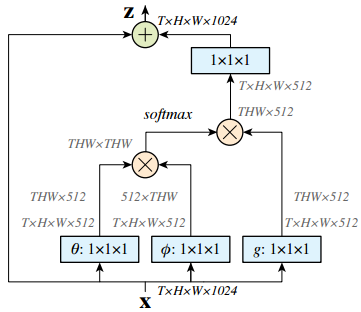
与其说AI智能时代,不如说是“泛智能的自动化”时代,或者,以人类为智能核心的 “机器智能辅助”时代 — David 9
最近流传的一些AI“寒冬论”, David 9 觉得很可笑。二十年前深蓝击败卡斯帕罗夫时,自动化智能已经开始发展,只是现今更“智能”而已,而这个更智能、更普及的趋势不是任何人可以控制的。
人类无尽的贪婪和惰性需要外部智能辅助和填补,也许以后的核心不是“深度学习”或者增强学习,但终究会有更“好”的智能去做这些“脏”活“累”活,那些人类不想干或人类做不到的活。。。
CVPR2018上,伊利诺伊大学和Intel实验室的这篇“学会在黑暗中看世界” 就做了人类做不到的活, 自动把低曝光、低亮度图片进行亮度还原:

人肉眼完全开不到的曝光环境下,机器实际是可以还原出肉眼可识别的亮度。
该论文的第一个贡献是See-in-the-Dark (SID)数据集的整理:
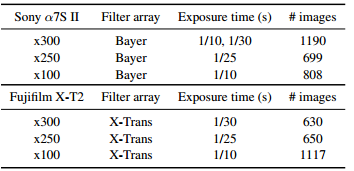
因为目前的数据集没有针对低曝光同时低亮度的图片集,如上图,作者用索尼和富士相机收集低曝光的室内室外图片,同时配对正常曝光的图片用来训练: 继续阅读CVPR2018精选#3: 端到端FCN学会在黑暗中看世界,全卷积网络处理低曝光、低亮度图片并进行还原,及其TensorFlow源码