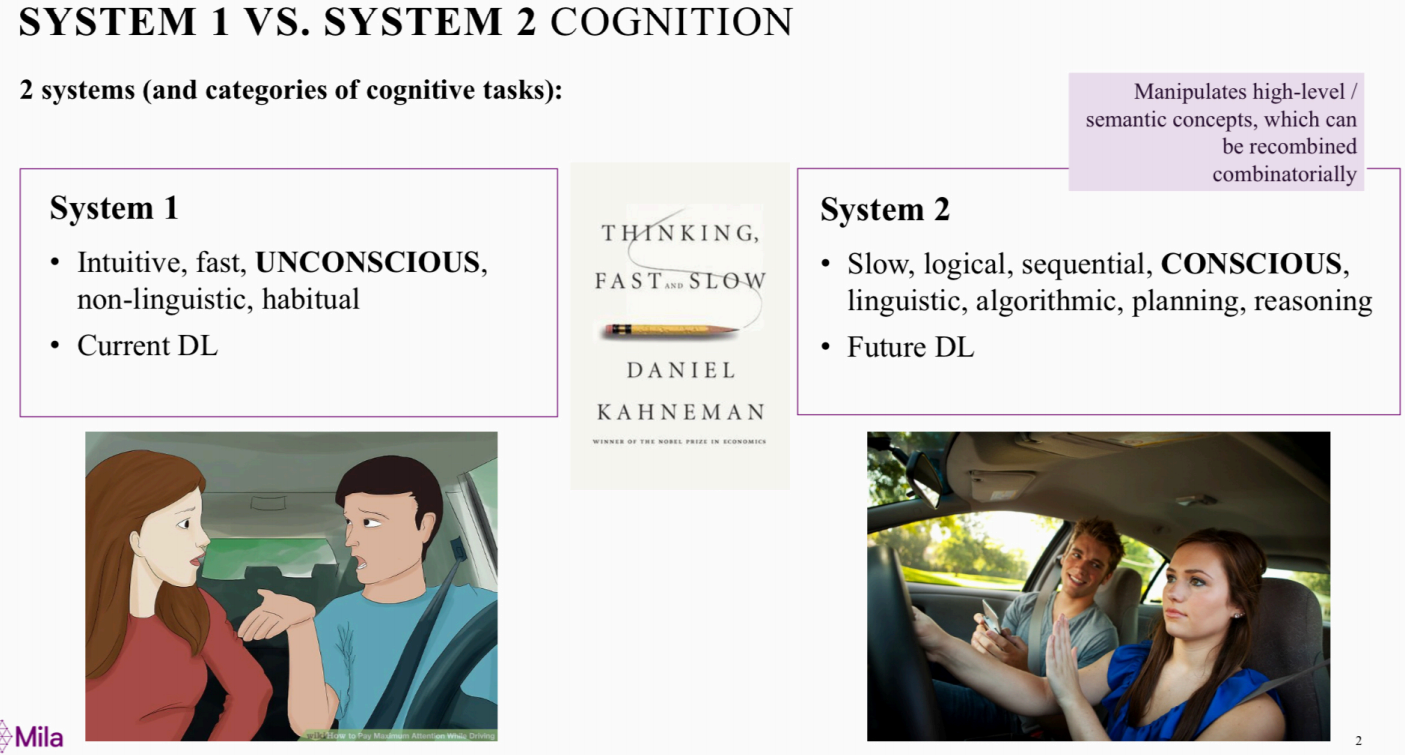
“端到端”学习是个“童话”,讲给懒人听的“童话” — David 9
记得听说“端到端”学习时的感受吗?有人告诉你只要准备训练数据集,其他的什么也不用做,等着模型收敛就行,就像有人告诉你上帝造了亚当,只需接受,不用怀疑。但是当实践时,所谓的“卖点”完全不是那么回事,代码不work要内部调试,模型性能差也要内部调优。
如果你运气好不用调试也不用调优,那么来自AMLab(阿姆斯特丹机器学习实验室)的这篇文章还会给你至少3个理由, 指出“端到端”的问题:
1. 所有的“端到端”深度模型每次迭代都需要对整体进行反向传播,这就意味着显存GPU的大量消耗: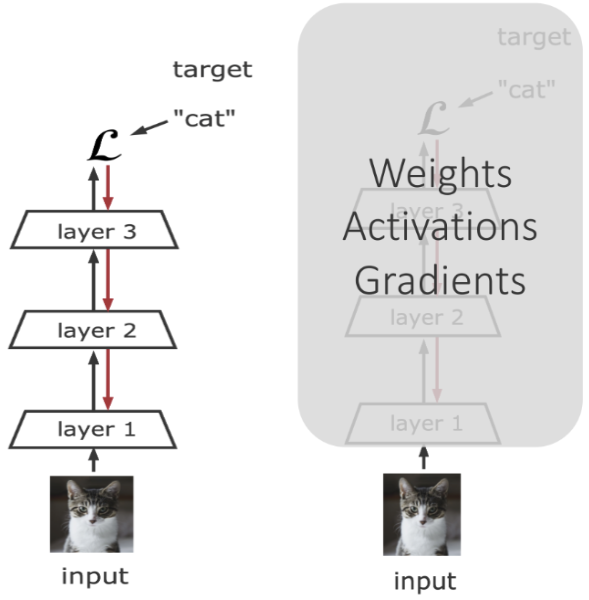
2. 如果实现了分层隔离的神经网络模型,可以更高效地采用分布式或边缘计算。
3. 生物界或自然界普遍不是完全“端到端”的,记得我们之前讲过的脉冲神经网络吗?拿神经元举例,信息传递不是直入直出的,神经网络是有延时的,大脑和皮肤不是直接共享信息的,而是由中间的绿色兴奋区域(active zone)做中转的,脑皮层的神经元如果需要信息,他会自己去active zone拿:
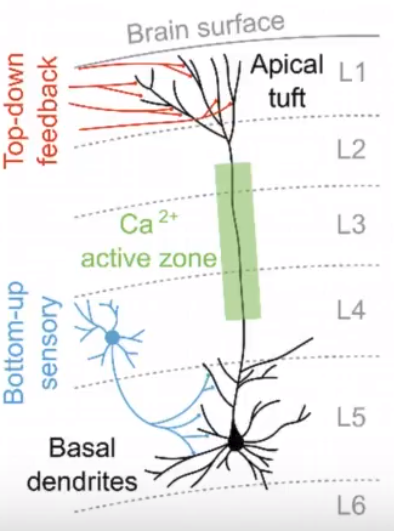
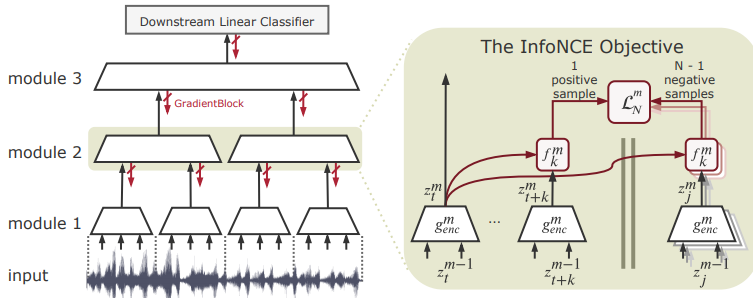
即,实际人类神经网络中的各个模块的独立性或许超出的我们的想象。换句话说, 继续阅读“去端到端”化和复杂loss:梯度隔离的分层神经网络模型Greedy InfoMax(GIM),深入了解自监督学习#2,InfoNCE loss及其对分层脉冲神经网络的启发