每一次挫败都值得“反复咀嚼”,人类和AI都应如此,而人类似乎从中感受更多的痛苦。也许这种痛苦源于更“高层”的“感知”。 — David 9
人类许多痛苦来源于无法躲避的事物和想要躲避的“主观”(潜意识或非潜意识)。所以,懂得和“情绪”好好相处被视为“高情商”;懂得和“失败”好好相处被视为“智慧”。那么,好好和“数据”相处,恐怕也是AI模型的进步。
不得不承认,没有任何数据集是完全干净的。除去人工标注的错误,单个样本的标签也有歧义,下图是ImageNet中的噪声图像:
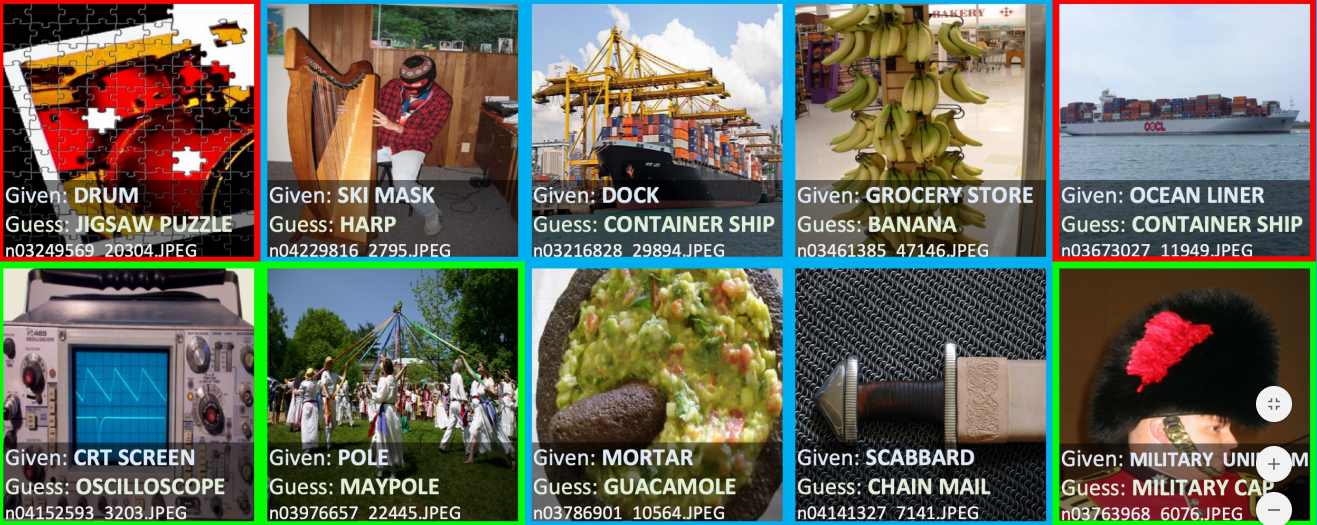
图像中的拼图(PUZZLE)上画着鼓(DRUM),那么这张图像分类应该是“拼图”还是“鼓”?超市(GROCERY STORE)内部的照片有香蕉(BANANA)的货架,那么这张图像应该归为“超市”还是“香蕉”?
同样MNIST也有难分的图像:

这些广泛存在的噪声数据,如果不和这些数据“好好相处”,任何普通的神经网络和传统算法都无可奈何(因为低级感知无法感知语义歧义)。
在不改变模型情况下,MIT和Google的研究人员试图用所谓的“信心学习”(Confident learning)方法,半监督的方式清洗数据。
先看一眼整体框架: 继续阅读CL“信心学习”: 专注样本质量的训练,MIT与谷歌的半监督新方法,Confident learning原理与代码cleanlab