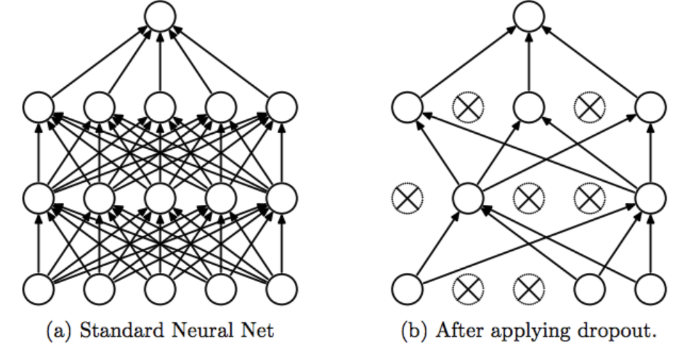
Numpy无疑是入门数据科学或深度学习几乎必学的工具,感谢网友和David一起翻译改编了这篇blog帮助大家对numpy闪电入门和整理:
使用numpy包的时候一般是从下面这句代码开始的:
import numpy as np
####创建数组
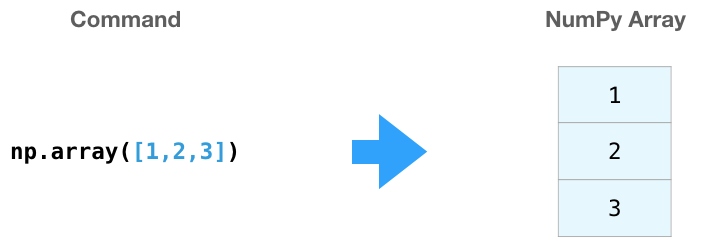
使用np.array()函数,这个函数的参数可以是列表,来创建一个nunpy数组:
 还可以通过其他的方式创建数组,并初始化。比如说ones(), zeros(), random.random():
还可以通过其他的方式创建数组,并初始化。比如说ones(), zeros(), random.random():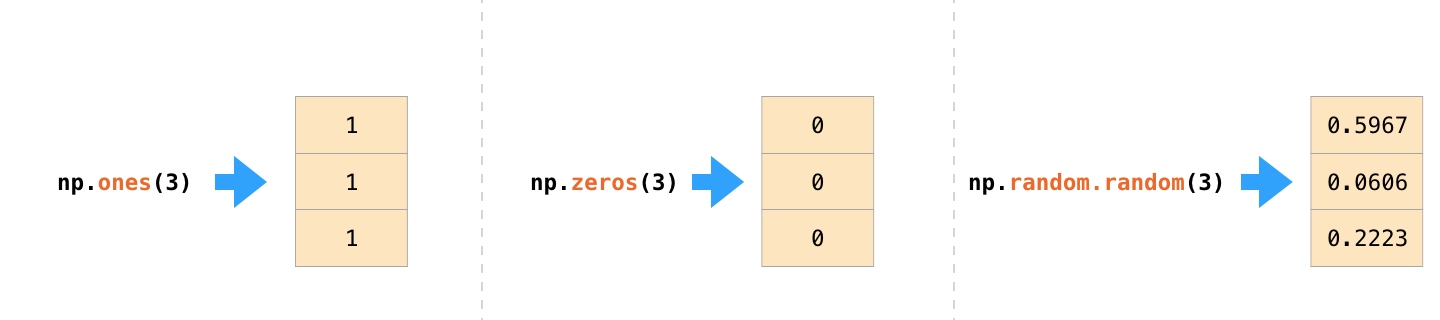
一旦我们创建了数组,我们就可以对它们进行操作了。
####数组操作
首先创建两个数组,并将它们分别命名为data, ones:
将两个数组相加,它这个操作会对对应位置的数组元素进行相加并赋值到新的数组: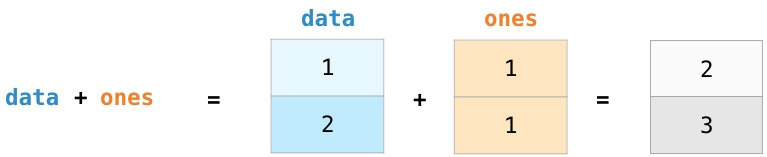 不仅仅可以进行加法操作,还可以进行其他的运算:
不仅仅可以进行加法操作,还可以进行其他的运算: 我们还可以进行数组和标量之间的运算,这种形式叫做广播:
我们还可以进行数组和标量之间的运算,这种形式叫做广播:
如果要快速合并两个数组(或矩阵),vstack和hstack是很好的工具,
vstack是以”行”的方式合并,hstack是以”列”的方式合并: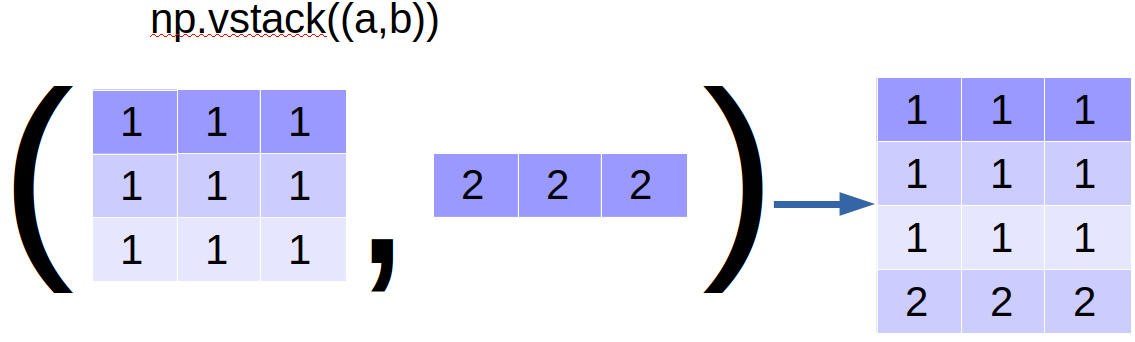
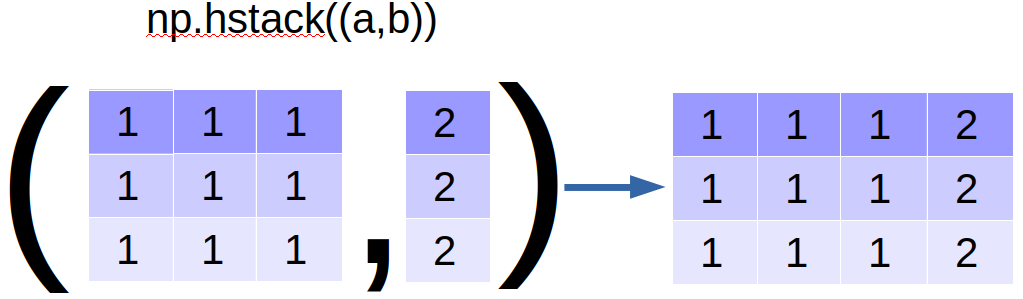
还可以同时合并多个array或矩阵: 继续阅读看图闪电入门Numpy,Numpy数据结构,David9的np.array日常