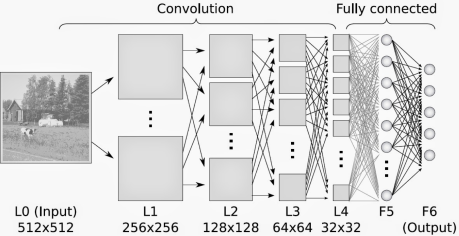
上一期我们讲到Pycon 2016 tensorflow 研讨会总结 — tensorflow 手把手入门 #第二讲 word2vec . 今天是我们第三讲, 仔细讲一下CNN.
所讲解的Workshop地址:http://bit.ly/tf-workshop-slides
示例代码地址:https://github.com/amygdala/tensorflow-workshop
首先什么是CNN? 其实, 用”人话”简洁地说, 卷积神经网络关键就在于”卷积”二字, 卷积是指神经网络对输入的特征提取的方法不同. 学过卷积的同学一定知道, 在通信中, 卷积是对输入信号经过持续的转换, 持续输出另一组信号的过程.
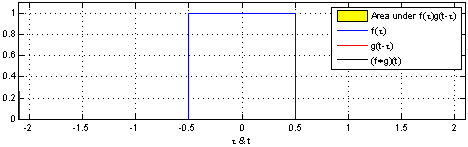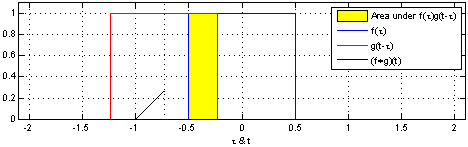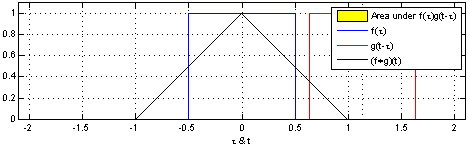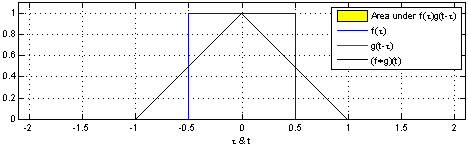
上图来自维基百科, 经过红色方框的持续转换, 我们关注红色方框和蓝色方框的重叠面积, 于是我们得到新的输出: 黑色线的函数. 这正是通过卷积生成新函数的过程. 继续阅读Pycon 2016 tensorflow 研讨会总结 — tensorflow 手把手入门, 用”人话”解释CNN #第三讲 CNN

 表示集成后模型的泛化误差.
表示集成后模型的泛化误差. 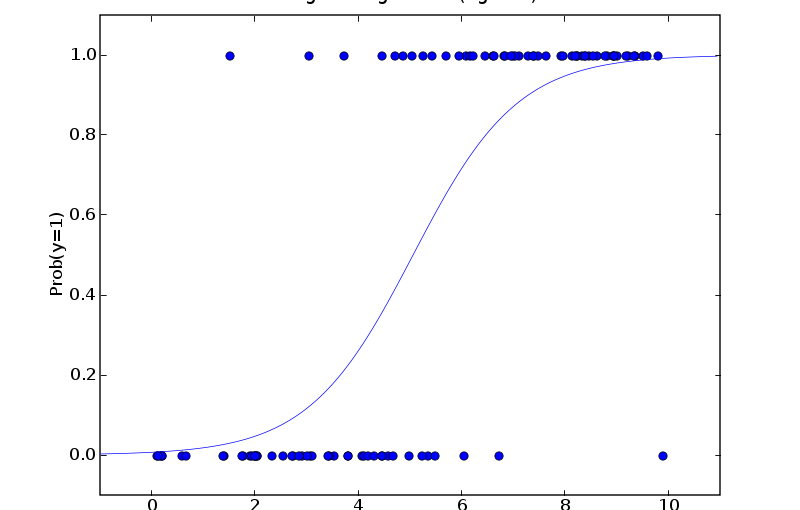
 , 注意这里
, 注意这里 可以都是高维向量
可以都是高维向量