上一期的Pycon 2016 tensorflow 研讨会总结 — tensorflow 手把手入门 #第二讲 中, 谈到过word2vec, 但是究竟什么是Word2vec ? 以及skip-Gram模型和CBOW模型究竟是什么? 也许还有小伙伴不是很明白, 这一次我们来好好讲一下这两种word2vec:
- 连续Bag-of-Words (COBW)
- 从上下文来预测一个文字
- Skip-Gram
- 从一个文字来预测上下文
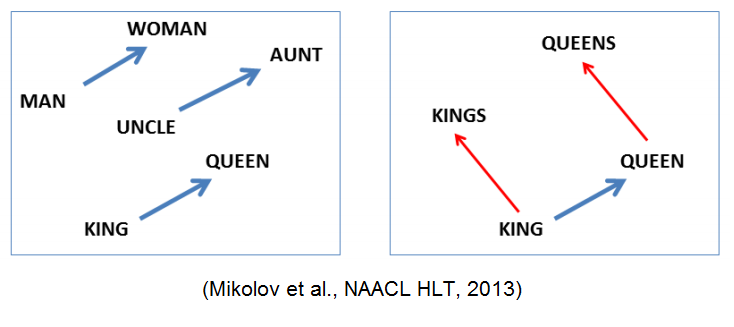
其实, 用一个向量唯一标识一个word已经提出有一段时间了. Tomáš Mikolov 的word2vec算法的一个不同之处在于, 他把一个word映射到高维(50到300维), 并且在这个维度上有了很多有意思的语言学特性, 比如单词”Rome”的表达vec(‘Rome’), 可以是vec(‘Paris’) – vec(‘France’) + vec(‘Italy’)的计算结果.
接下来, 上word2vec示意图:
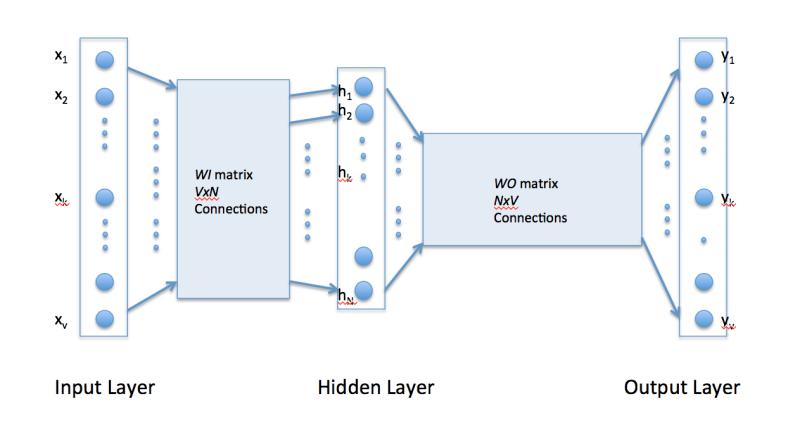
很显然, word2vec是只有一个隐层的全连接神经网络, 用来预测给定单词的关联度大的单词. 继续阅读究竟什么是Word2vec ? Skip-Gram模型和Continuous Bag of Words(CBOW)模型 ?