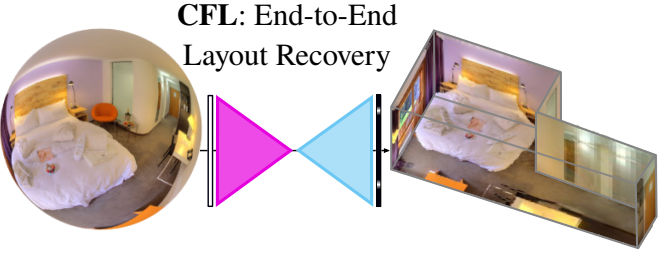
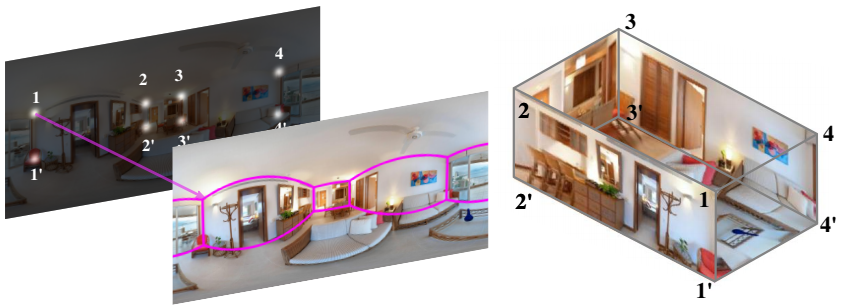
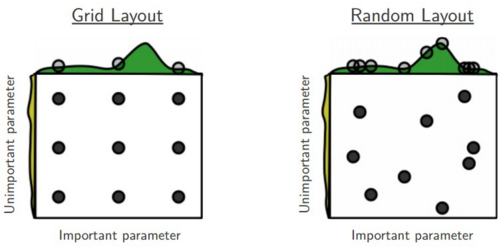
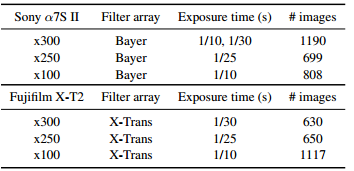
20 美元/时的AutoML太贵?试试AutoKeras吧
自动搜索构建深度学习模型和调参一直是数据科学家们向往的工具,而我们知道Google AI发布的AutoML是要收费的,如果想要开源的而且想要对AutoML背后技术一探究竟的,可以看看这款AutoKeras,

AutoKeras开发处于初期阶段,它基于Keras(也有pytorch),而keras我们知道是基于TensorFlow,所以GPU利用可以不用担心(只要你安装了gpu版TensorFlow即可)。由于Keras代码极其简洁,autokeras上手也较容易 。
所以直接上autokeras版mnist训练代码:
from keras.datasets import mnist
from autokeras.image_classifier import ImageClassifier
if __name__ == '__main__':
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(x_train.shape + (1,))
x_test = x_test.reshape(x_test.shape + (1,))
clf = ImageClassifier(verbose=True, augment=False)
clf.fit(x_train, y_train, time_limit=12 * 60 * 60)
clf.final_fit(x_train, y_train, x_test, y_test, retrain=True)
y = clf.evaluate(x_test, y_test)
print(y * 100)
这里有几个要点,第一,代码需要在python3.6上跑否则会有兼容性问题(目前autokeras只支持python3.6), 继续阅读AutoKeras:开源AutoML初体验,自动搜索和构建最优深度模型,贝叶斯搜索器,以及mnist示例代码