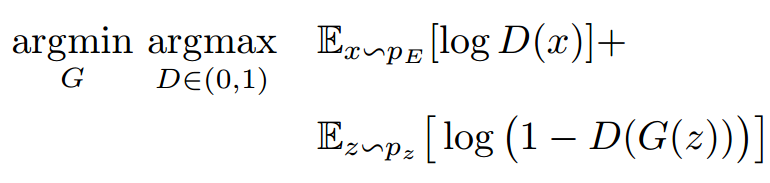
嘿,你这个叫GAIL小家伙,跟着大人学的时候,自己也要看看下一步— David 9
接着上次的GAIL讨论(GAN+增强学习),我们还有一个坑未填。即,基于模型的GAIL对抗模仿学习。首先回顾一下强化学习的简单体系:
1. 如果RL(强化学习)训练中给出回报(reward),其算法有我们熟悉的价值迭代value iteration算法和策略policy iteration算法,以及DPL(Direct Policy Learning假设一个policy)。
2. 如果没有明确回报(reward)给出,就涉及到更有意思的模仿学习IRL(Inverse Reinforcement Learning)。 一个实际的例子就是上次聊到的GAIL算法,简单说是假设回报函数,用GAN去识别目前的策略是否符合假设的回报函数(应有的策略):
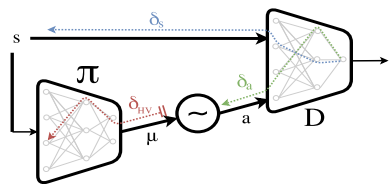
此处GAIL就产生一个问题,如上图,GAN的判别器D可以判别生成器的策略和被模仿对象(专家策略)之间的区别,但是,当把行为错误δa反向传播时,只能估算一个大概的梯度δHV 给生成器(往往不稳定并且高方差的)。这就导致一个很明显的漏洞,这个判别器D只能根据当前的行为a、被模仿者的状态x1和模仿者的状态x2做判别,如果模仿者和被模仿者像下面这样:
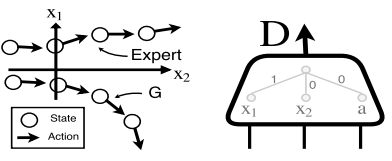
只要判断x1和x2正负就能轻松判别两种策略,那么梯度也没有办法获得,问题就出在:我们没有把模仿者G的趋势也与Expert专家策略的趋势结合起来,使得Expert策略一直往上走,而G的策略一直往下走,判别器D也浑然不知策略出了问题。
为了使趋势也能在梯度上体现,不出意料文章要使出RNN或者马尔科夫链的技能,即加入时序组件:
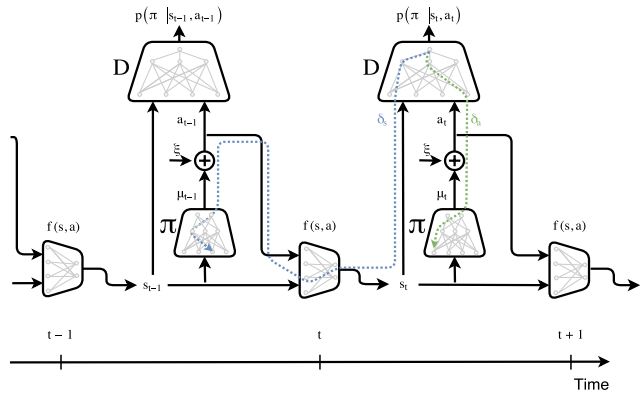
如上图,两个重复的模块即串连起来的两个时刻t 和 t+1, 把时序串连起来的是一个新增的网络 f(s,a),它的输入是上个状态St-1,以及模仿者G(策略π)的行为抽样a,输出是预测的下个状态St 。这样有了模仿者G的预测状态St,模型就知道G的状态趋势。判别器D就能更好地判别模仿者和被模仿者的差异。
小时候,大人会告诉小孩:“小家伙,跟大人学的时候,自己也要自己看着点 ”。没错,GAIL模型以及今后所有追逐强AI 的模型也许都需要自己向后看一步,或者多步, 因为我们都是独一无二的个体,我们的模仿不可能只是照搬模仿对象。
参考文献:
本文采用署名 – 非商业性使用 – 禁止演绎 3.0 中国大陆许可协议进行许可。著作权属于“David 9的博客”原创,如需转载,请联系微信: david9ml,或邮箱:yanchao727@gmail.com
或直接扫二维码:

David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024