一切高级智能的优化过程, 要有尽可能少的人为干预, 也许有一天人们会明白, 强AI的实现是人类放弃”自作聪明”的过程 — David 9
当Deepmind拓展深度学习的边界, OpenAI似乎对强AI和强化学习更有执念, 前些时候的进化策略算法(Evolution Strategy,以下简称ES算法) 在10分钟内就能训练一个master级别的MuJoCo 3D行走模型:

着实给了Deepmind强化学习一个下马威.
ES算法摒弃了强化学习在行动Action域的惯性思维, 复兴了与遗传算法同是80年代的进化策略算法思路。达到了目前强化学习也能有实验结果. 先来看看ES和遗传算法的异同:

没错, 像上面指出的, ES算法和遗传算法的思路非常相似, 只是前者适用于连续空间, 后者更适用于离散空间.
那么ES算法和RL强化学习又有什么差别呢 ?
我们之前说过, 强化学习的最小学习粒度就是一个个Action和一个个状态State, 所以更新策略时只能抽样Action来获得学习反馈, 从而迭代得到更好的策略函数:
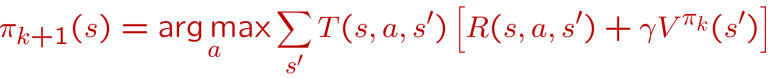 但是,ES算法粒度就小的多, 不是人为去抽样一个个Action, 而是抽样策略函数中的参数. 对于下图的神经网络训练:
但是,ES算法粒度就小的多, 不是人为去抽样一个个Action, 而是抽样策略函数中的参数. 对于下图的神经网络训练:
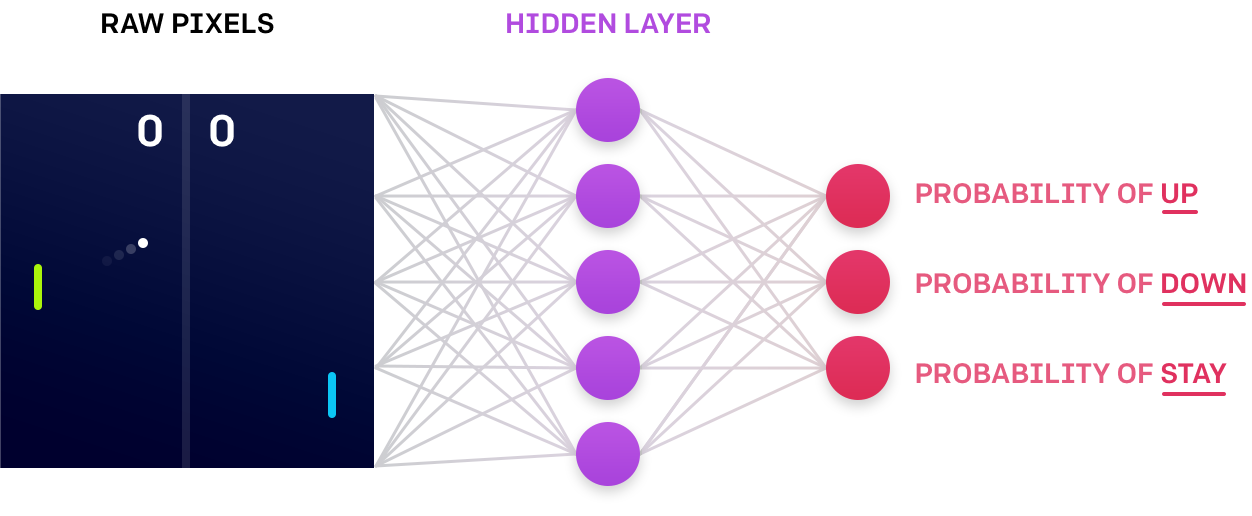 RL算法会抽样输出值来调整神经网络权重; 而ES算法会抽样神经网络内部参数, 跑一些”演练”, 从而更新得到更好的内部参数.
RL算法会抽样输出值来调整神经网络权重; 而ES算法会抽样神经网络内部参数, 跑一些”演练”, 从而更新得到更好的内部参数.
因此可以理解ES算法为: 通过扰动模型内部参数, 获得多个候选模型, 最后根据回报值更新得到更好的内部参数:
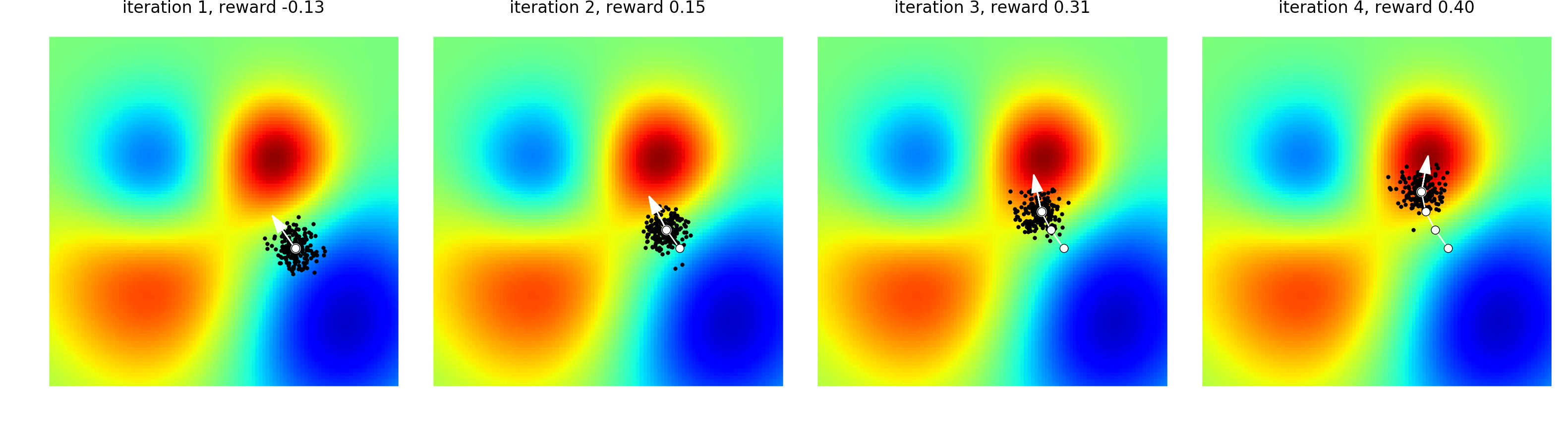 上图为一个ES优化过程, 白点代表当前模型内部参数, 周围的黑点是抽样的噪声参数, 对所有的噪声参数计算一个回报向量,根据这些回报向量,可以调整内部参数到一个更好的值。
上图为一个ES优化过程, 白点代表当前模型内部参数, 周围的黑点是抽样的噪声参数, 对所有的噪声参数计算一个回报向量,根据这些回报向量,可以调整内部参数到一个更好的值。
ES算法归结为如下等式:
![]()
F可理解为价值评价函数(目标函数),θ为模型内部参数,θ用分布p来抽样。ψ为p分布的内部参数。ES等式告诉我们:
如果我们想优化价值评价函数F的内部参数,我们可以看等式右边,先抽样一些内部参数θ,计算这些θ下的评价值F(θ),同时计算第二项logpψ(θ), 即ψ应该在哪个方向上更新,才可能得到想要的θ:
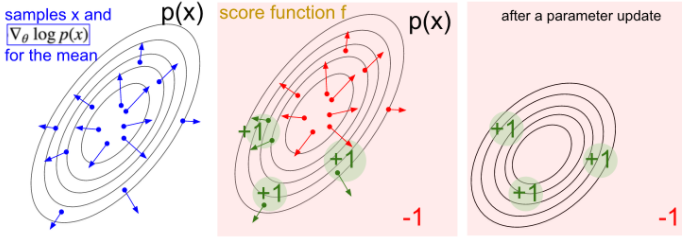
为了方便计算,文章对p采用高斯分布:
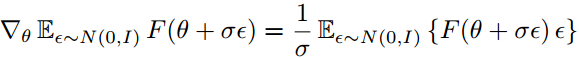 对应的算法如下:
对应的算法如下:

幸运的是,这种算法是可以高并行的:
 我们可以在许多个节点分别计算模型Fi的评价,最后把这些评价集中起来,更新θ参数。
我们可以在许多个节点分别计算模型Fi的评价,最后把这些评价集中起来,更新θ参数。
最后看一下实验结果:
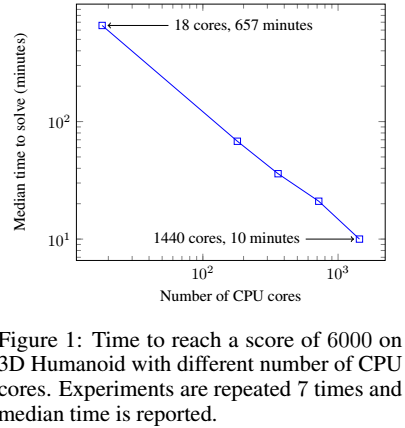 ES算法高度的并行性,使得快速训练成为可能,上图是在3D行走模拟的结果。在1440个核并行计算下,可以在10分钟内到达一个较好的结果。
ES算法高度的并行性,使得快速训练成为可能,上图是在3D行走模拟的结果。在1440个核并行计算下,可以在10分钟内到达一个较好的结果。
ES算法的另一个好处是,对于Action行动频率是不敏感的:
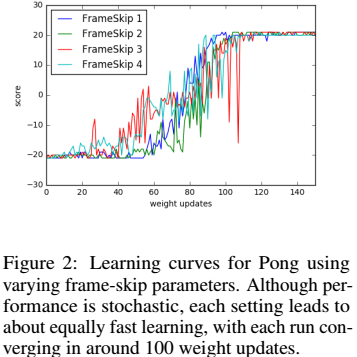

即,无论在乒乓游戏中移动平板的频率设置为“快”或“慢”,最终的回报得分都是差不多的。如想深入理解,不如看看ES源码。
本质上,普通的梯度下降等求导的优化算法,人们可以显式地看到内部神经网络权重因外部监督而调整; 而ES优化算法随机性更强,如果你有一组Action测试数据,你不能预测下一步网络内部权重如何变化,所以许多人把这种优化算法叫做“黑盒优化”。
参考文献:
- Evolution Strategies as a Scalable Alternative to Reinforcement Learning
- https://www.youtube.com/watch?v=C4MUTIc-NB8&t=501s
- https://blog.openai.com/evolution-strategies/
- http://karpathy.github.io/2016/05/31/rl/
- https://blog.openai.com/evolution-strategies/
- https://en.wikipedia.org/wiki/Random_optimization
本文采用署名 – 非商业性使用 – 禁止演绎 3.0 中国大陆许可协议进行许可。著作权属于“David 9的博客”原创,如需转载,请联系微信: david9ml,或邮箱:yanchao727@gmail.com
或直接扫二维码:

David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024