
学习的第一要素从来都不是“模仿”或“收获知识”,学习要有“控制感” !— David 9
近来,研究人员似乎更加执着地认为,类似BERT, GPT等大型语言模型的训练方式也可以在视觉图像领域一展拳脚(pretrain+finetune)。
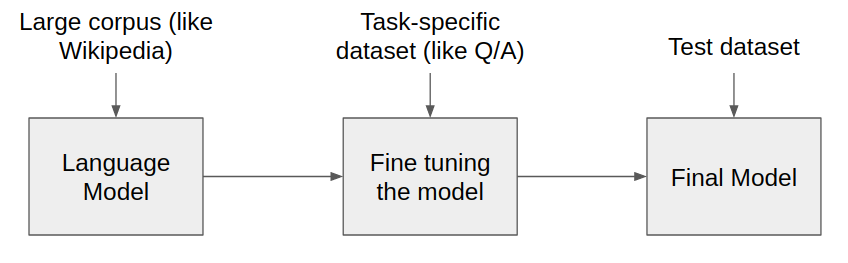
其中包括Image GPT 和 SimCLRv2 。当然照搬BERT,GPT到图像域是不可能的。这两个框架都采用各自独特的方法做(pretrain+finetune)稍后David将详细讲述两者区别。
David首先要强调的是,所有目前看来“先进的”算法(“预训练”,“自监督”甚至像GPT这样的大模型)都只是人们最大限度把自己的先验传导到模型,把最大自由度留给算力的过程。所以请允许我提一点猜想:
先验流(阻力)假设:人的先验传导到机器域是有阻力的。当模型能更高效率地传导人的先验,那么模型的学习效果就更好。— David 9
以这个假设,即使人类现在的模型架构原地踏步,只要人类的硬件和计算力在不断增强,训练数据不断增加,模型总能更高效地“吸收”人的先验。
扯远了,要真正提高“先验传导”,还是要从模型下手。
Google前不久的文章(Rethinking Pre-training and Self-training)就比较了“预训练”和“自监督”的优劣,直接说PK结果:
使用自监督(self-training)技巧的模型