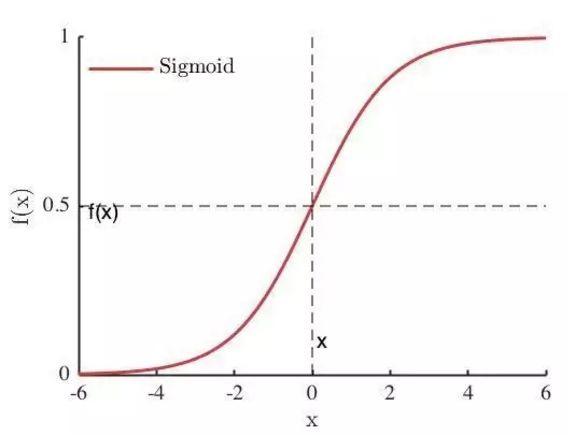
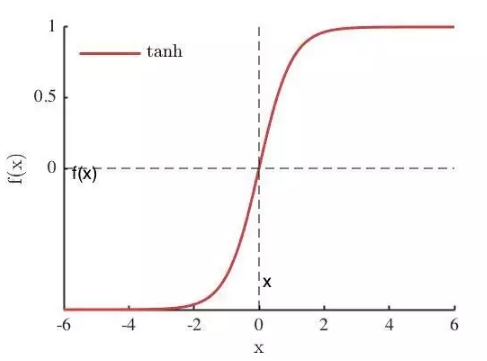
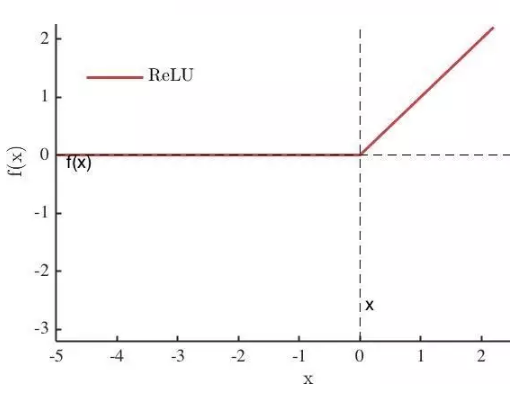
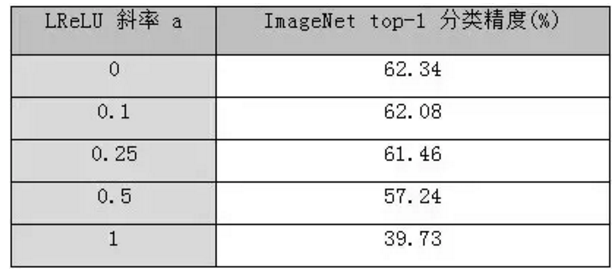
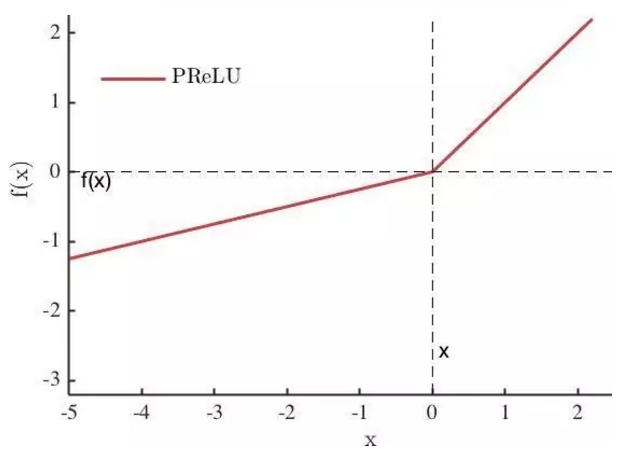
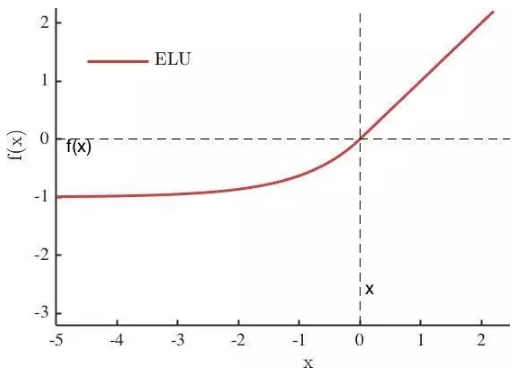
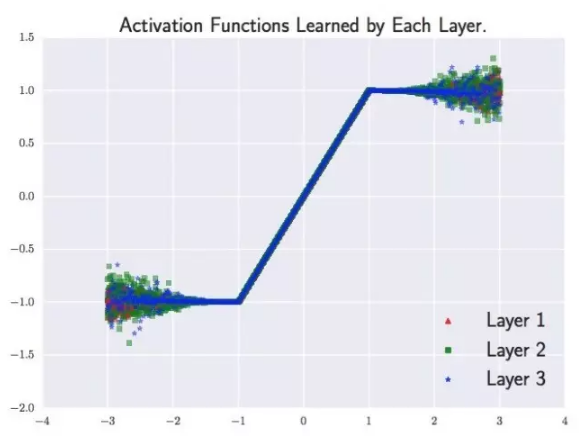
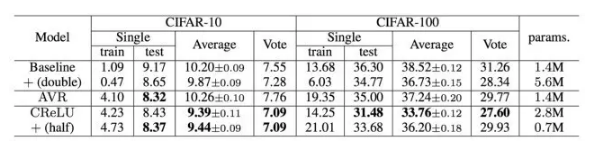
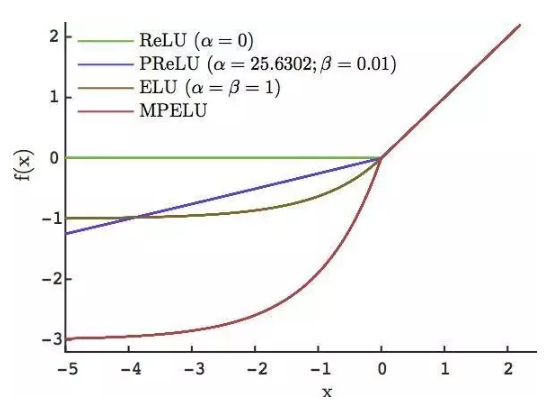
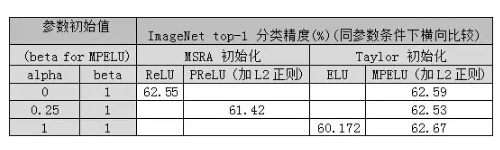
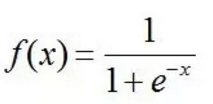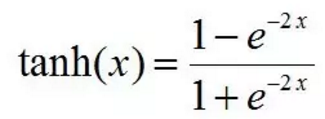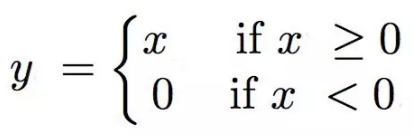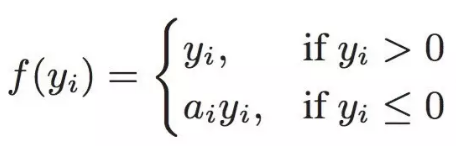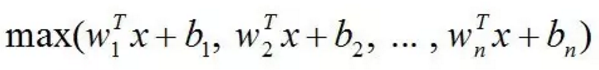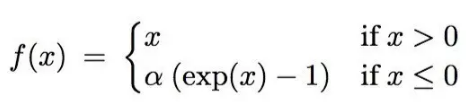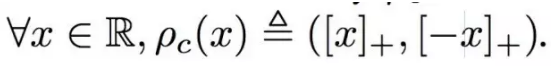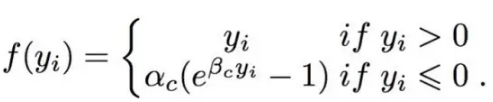Maxout[13]是ReLU的推广,其发生饱和是一个零测集事件(measure zero event)。正式定义为:Maxout网络能够近似任意连续函数,且当w2,b2,…,wn,bn为0时,退化为ReLU。 其实,Maxout的思想在视觉领域存在已久。例如,在HOG特征里有这么一个过程:计算三个通道的梯度强度,然后在每一个像素位置上,仅取三个通道中梯度强度最大的数值,最终形成一个通道。这其实就是Maxout的一种特例。Maxout能够缓解梯度消失,同时又规避了ReLU神经元死亡的缺点,但增加了参数和计算量。
1. Gulcehre, C., et al., Noisy Activation Functions, in ICML 2016. 2016.2. Glorot, X. and Y. Bengio. Understanding the difficulty of training deep feedforward neural networks. AISTATS 2010.3. LeCun, Y., et al., Backpropagation applied to handwritten zip code recognition. Neural computation, 1989. 1(4): p. 541-551.4. Amari, S.-I., Natural gradient works efficiently in learning. Neural computation, 1998. 10(2): p. 251-276.5. Nair, V. and G.E. Hinton. Rectified linear units improve Restricted Boltzmann machines. ICML 2010.6. Glorot, X., A. Bordes, and Y. Bengio. Deep Sparse Rectifier Neural Networks.AISTATS 2011.7. Djork-Arné Clevert, T.U., Sepp Hochreiter. Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs). ICLR 2016.8. Li, Y., et al., Improving Deep Neural Network with Multiple Parametric Exponential Linear Units. arXiv preprint arXiv:1606.00305, 2016.9. Xu, B., et al. Empirical Evaluation of Rectified Activations in Convolutional Network. ICML Deep Learning Workshop 2015.10. He, K., et al. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. ICCV 2015.11. He, K. and J. Sun Convolutional Neural Networks at Constrained Time Cost. CVPR 2015.12. Maas, A.L., Awni Y. Hannun, and Andrew Y. Ng. Rectifier nonlinearities improve neural network acoustic models. in ICML 2013.13. Goodfellow, I.J., et al. Maxout Networks. ICML 2013..14. Shang, W., et al., Understanding and Improving Convolutional Neural Networks via Concatenated Rectified Linear Units.ICML 2016.15. Mishkin, D. and J. Matas All you need is a good init. ICLR 2016.该文章属于“深度学习大讲堂”原创,如需要转载,请联系loveholicguoguo。作者简介:李扬,北京邮电大学电子工程学院通信与网络中心实验室博士生,导师范春晓教授。本科毕业于合肥工业大学光信息科学与技术专业,硕士师从北京邮电大学杨义先教授学习并从事信息安全项目研发。2015年转向深度学习领域,目前专注于深度学习及其在目标检测的应用。