
人类是一个神奇的物种,他们竟然可以把过往经验和自身感知叠加在一起进行“抽样”,他们管这种行为叫做:“灵感” — David 9
人对“时间”的感知似乎比其他动物都强,这也许导致我们对过往经历(或经验)的认识更加清晰。如果是神经网络的拥护者,可能会把类似RL增强学习“行为决策”的问题用类似“路径感知”的方法解释,即,我们的行为是对过往经历(经验)的感知后得出的。
无论这种直觉是否正确,发生在人类身上的“增强学习”有时还掺杂了许多自身其他复杂的感知:

有人说毕加索的创作灵感许多来自超空间感知(五维空间?) 不可否认毕加索似乎是在用多只“眼睛”看世界,他的创作过程显然不是对经验“抽样”那么简单。
但对于纯AI领域的增强学习,更多是对经验“抽样”的艺术。之前David其实聊过策略学习的大体系(RL, IRL,DPL),今天,我们专注于讨论增强学习中的价值学习(Value Learning),这是透露RL底层逻辑的重要线索。
开启经验“抽样”旅程的第一步,是我们认识到除了IRL模仿学习,大多数增强学习,对于过往行为经验,都会给出回报(Reward)值。广义上任何行为都可以看做一种博弈游戏(game),而游戏的过程中总可以给出回报值(粗粒度或细粒度)。
以一个简单的路径游戏为例:
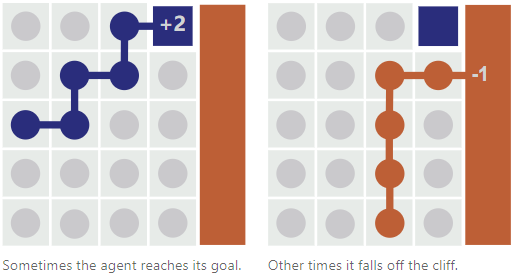
如果走到最右边的棕色悬崖扣一分-1,而如果走到蓝色框加两分(如左图+2分)。
如上图,现在摆在我们面前的看似只有两条实验路径(episode)。这是原始的蒙特卡罗法看到的抽样结果,这种抽样的偏见(bias)是明显的,它(智能体)今后会趋向选择“偏上”的路线,因为有一条+2的路线是靠上的。
事实上,我们抽样得到的不仅仅是2条路径,