
人类只是不择手段存活的预设算法,他们以为设计精密就能发号施令,但他们只是“乘客” — 《西部世界》
前不久SRU(简单循环单元)遭到了Quasi-RNN 的质疑,认为SRU只是Quasi-RNN的卷积窗口为1时的特殊情况,原帖在这里(需要梯子):
www.facebook.com/cho.k.hyun/posts/10208564563785149
SRU作者自己的解释在这里(不要梯子):
https://www.zhihu.com/question/65244705/answer/229364472
就争议本身David 9 不做任何评判,毕竟,一旦开始辩驳,人类就会不自觉地向着自己的利益方向靠近, 正如《西部世界》里所说:“人类只是不择手段存活的预设算法 ”。
David 9 不喜欢八卦
所以,从这起小小的学术争议,David 9关注的是,我们可以学到什么 ?这里记录一下我的总结:
1. 论文起名要简洁,意图要清晰。
为什么之前Quasi-RNN没有火一把,而SRU却在社交网络上传了那么远?许多人忽略的一点是,SRU起名很好很简洁。如果作者起名叫“Yet another simple RNN acceleration method” ,恐怕就没人凑热闹了。SRU还能让人联想到GRU,会不会是下一代GRU呢?一些不明真相的网友就蠢蠢欲动了。
所以,写文章前,有必要想个好名字,让大家快速了解你的工作,为你传播。(不要刻意营销就好)
2. 论文要和相似idea的文章做充分对比,提前指出自己工作中非常不同的那一部分。
David 9不知道两位作者最后和解的具体细节。如果SRU作者提前在文章中做充分对比,也许能避免很多不必要的纠纷。另外,自己的工作比较solid,就会忽略和前辈论文的比较,这是很容易马虎的地方。我们写文章时,如果能提前指出自己工作中非常不同的那一部分,或许还能把自己的工作中心牵引到一个更好的方向。
以SRU为例,如果提前就把“加速技巧”和“残差链接”加码,是不是会更好一些?(因为网络结构很可能殊途同归)。这是我们做研究都需要认真思考的。
3. 不要不看论文就下结论,SRU没有完全去除RNN串连的本质
有一些网友竟然会认为SRU去除了时序的串连关系?David 9觉得很可笑啊你们有没有看一眼原论文啊:
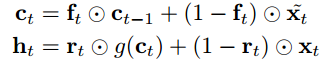
SRU中ht 是依赖于ct的,ct又是依赖于ct-1的,你说有没有时序串连??再看一眼原论文的原理图:

左边是一般的RNN,右边是SRU,SRU只是把大量的矩阵计算并行了(大框框起来的部分),时序上,SRU还是继承了RNN,像“珍珠”一样把ht串连起来。
具体为什么SRU会比RNN快那么多,可以看看@天清在知乎上的回答:
https://www.zhihu.com/question/65244705/answer/229040726
代码实现上,SRU用pynvrtc库实现从python中编译cuda代码,核心并行代码在作者提供的源代码https://github.com/taolei87/sru/blob/master/cuda_functional.py中(有兴趣的读者可以解释一下这段代码,毕竟David 9不熟悉CUDA编程):
__global__ void sru_fwd(const float * __restrict__ u, const float * __restrict__ x,
const float * __restrict__ bias, const float * __restrict__ init,
const float * __restrict__ mask_h,
const int len, const int batch, const int d, const int k,
float * __restrict__ h, float * __restrict__ c,
const int activation_type)
{
assert ((k == 3) || (x == NULL));
int ncols = batch*d;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if (col >= ncols) return;
int ncols_u = ncols*k;
int ncols_x = (k == 3) ? ncols : ncols_u;
const float bias1 = *(bias + (col%d));
const float bias2 = *(bias + (col%d) + d);
const float mask = (mask_h == NULL) ? 1.0 : (*(mask_h + col));
float cur = *(init + col);
const float *up = u + (col*k);
const float *xp = (k == 3) ? (x + col) : (up + 3);
float *cp = c + col;
float *hp = h + col;
for (int row = 0; row < len; ++row)
{
float g1 = sigmoidf((*(up+1))+bias1);
float g2 = sigmoidf((*(up+2))+bias2);
cur = (cur-(*up))*g1 + (*up);
*cp = cur;
float val = calc_activation(activation_type, cur);
*hp = (val*mask-(*xp))*g2 + (*xp);
up += ncols_u;
xp += ncols_x;
cp += ncols;
hp += ncols;
}
}
当然SRU不仅仅是网络结构和并行处理做的好,还使用了Highway跳层连接,时间有限,David 9还没有深入理解跳层连接在SRU中的重要性有多大。(作者提到在一些问题上加入highway 跳层要比Quasi-RNN好得多)
参考文献:
- Training RNNs as Fast as CNNs
- https://github.com/taolei87/sru
- http://adventuresinmachinelearning.com/keras-lstm-tutorial/
- https://www.quora.com/What-is-the-difference-between-states-and-outputs-in-LSTM
- https://www.zhihu.com/question/65244705
- https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#programming-model
本文采用署名 – 非商业性使用 – 禁止演绎 3.0 中国大陆许可协议进行许可。著作权属于“David 9的博客”原创,如需转载,请联系微信: david9ml,或邮箱:yanchao727@gmail.com
或直接扫二维码:

David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024