人类擅长把一个问题转化为另一个问题,而深度学习试图把所有问题转化为同一个问题 — David 9
现代深度学习或机器学习,很大程度上是把所有问题转化为同一个“模型训练”问题。如何解决这个模型训练的问题成为了数据科学家们的主攻问题。
鲜为人知的是,设计机器学习模型、训练算法和目标函数仅仅是工作的一部分。还有很重要的一部分是:数据科学家们要对数据和问题有更深层次的理解,对于模型评估, 超参数调优,网格搜索,调试策略都有相当的实践经验。
正如Deep Learning(Ian Goodfellow Yoshua Bengio)一书中所说:
Correct application of an algorithm depends on mastering some fairly simple methodology
掌握一些简单的实战方法论,是不可或缺的增益。现在我们就把书中常用实战技巧总结给大家,相信有启示意义。
模型评估
按照Deep Learning一书中的说法是“性能度量”,但我更倾向于翻译为“模型评估”。“模型评估”看似是ML训练工作流的最后一步,但是这其实是要在拿到数据集时就应该认真考虑的。
所谓的测试集“预测准确率”或“错误率”在很多实际应用中是不够的。我们在一切训练工作前,就要确定一个实际有意义的目标。
比如,垃圾邮件检测系统会有两种错误:将正常邮件错误地归为垃圾邮件,将垃圾邮件错误地归为正常邮件。 阻止正常消息比允许可疑消息通过糟糕得多。
又比如,对于一种罕见疾病设计医疗测试。 假设每一百万人中只有一人患病。 我们只需要让分类器一直报告没有患者,就能轻易地在检测任务上实现99.9999%的正确率。 显然,正确率很难描述这种系统的性能。这就是常见的“非平衡集”预测。我们要关注的是那个极少量的标签。
对于非平衡集预测性能评估,我们有一个直观好用的工具:混淆矩阵
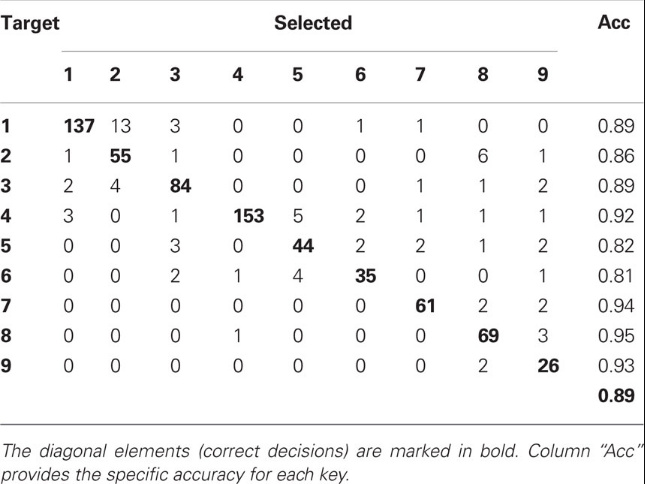
横向的是模型对类别的选择,纵向是真实的类别标签。所以落在对接线上的值是模型精确地分对类别的数量。对于特定应用,关注对角线是不够的,我们有时需要关注每个类各自的错误率(上图最右侧列);有时,我们需要关注当模型区分某个类时,它的正确率(观察上图每一列数值)。
当然,还有许多其他的性能度量。 例如,我们可以度量点击率、收集用户满意度调查等等。 许多专业的应用领域也有特定的标准。
否收集更多数据?
首先,确定训练集上的性能是否可接受。 如果模型在训练集上的性能就很差,学习算法都不能在训练集上学习出良好的模型,那么就没必要收集更多的数据。
如果训练集上的性能是可接受的,那么我们开始度量测试集上的性能。 如果测试集上的性能也是可以接受的,那么就顺利完成了。 如果测试集上的性能比训练集的要差得多,那么收集更多的数据是最有效的解决方案之一。
超参数调优
手动调整超参数
学习率可能是最重要的超参数。一张经典的图令人记忆深刻:
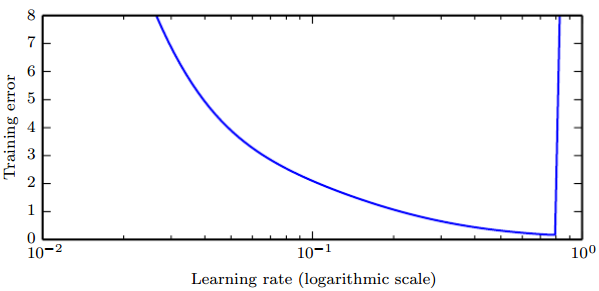
注意当学习率大于最优值时误差会有显著的提升。此图针对固定的训练时间,越小的学习率有时候可以以一个正比于学习率减小量的因素来减慢训练过程。泛化误差也会得到类似的曲线,由于正则项作用在学习率过大或过小处比较复杂。由于一个糟糕的优化从某种程度上说可以避免过拟合,即使是训练误差相同的点也会拥有完全不同的泛化误差。
调整学习率外的其他参数时,需要同时监测训练误差和测试误差,以判断模型是否过拟合或欠拟合,然后适当调整其容量。必须知道调整后对模型的影响,其中很重要的一个影响是模型容量(模型复杂度):

自动超参数优化算法
网格搜索
如果有三个或更少的超参数时,常见的超参数搜索方法是网格搜索。 对于每个超参数,使用者选择一个较小的有限值集去探索。 然后,这些超参数笛卡尔乘积得到一组组超参数,网格搜索使用每组超参数训练模型。 挑选验证集误差最小的超参数作为最好的超参数。
随机搜索
如果超参数较多, 首先,我们为每个超参数定义一个边缘分布,在这些边缘分布上进行搜索。
所以总结网格搜索和随机搜索,网格搜索是通过排列组合调整超参数,随机搜索是通过边缘分布调整超参数:
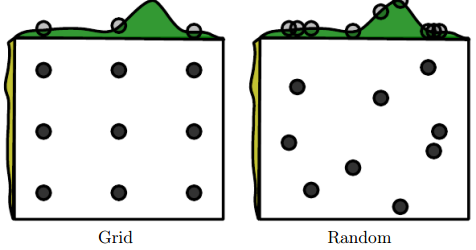
调试策略
当一个机器学习系统效果不好时,通常很难判断效果不好的原因是算法本身,还是算法代码编写错误。但是有一些小技巧可以记住:
- 观察模型行为,找到异常的错误行为。这个策略似乎非常简单,但是很多人都会忽视在训练完成之后,看看模型的预测行为,或者生成模型的生成行为有什么异常的地方。
- 观察训练误差和测试误差。如果训练误差较低,但是测试误差较高,那么很有可能训练过程是在正常运行,但模型由于算法原因过拟合了。 如果测试误差没有被正确地度量,可能是由于训练后保存模型再重载去度量测试集时出现问题,或者是因为测试数据和训练数据预处理的方式不同。 如果训练和测试误差都很高,那么很难确定是软件错误,还是由于算法原因模型欠拟合。
- 拟合较小数据集。现在一个小一点的数据集上跑训练,会有宏观的调试感觉。
- 打印有价值的log。在训练的每一轮,打印有价值的log,并且可视化。
- 许多深度学习的每一步迭代到下一次迭代都会有一系列影响和特征,如,目标函数值变小,梯度变小,这些影响和特征也是重要线索。
参考文献:
- https://github.com/HFTrader/DeepLearningBook
- http://machinelearningmastery.com/grid-search-hyperparameters-deep-learning-models-python-keras/
- https://deeplearning4j.org/questions.html
- https://github.com/exacity/deeplearningbook-chinese
- https://en.wikipedia.org/wiki/VC_dimension
本文章属于“David 9的博客”原创,如需转载,请联系微信: david9ml,或邮箱:yanchao727@gmail.com
或直接扫二维码:

David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024