
标题虽然是“入坑”,但David认为这个坑并不深,不变的规律是:人类的工具总是向简单易用发展(并且不妨碍强大的功能)。
TensorFlow 2.0最大更新(我认为没有之一)的积极模式(Eager Execution)同样如此。
也许你曾经喜欢PyTorch即拿即用即求导的简单快捷:
# Create tensors. x = torch.tensor(1., requires_grad=True) w = torch.tensor(2., requires_grad=True) b = torch.tensor(3., requires_grad=True) # Build a computational graph. y = w * x + b # y = 2 * x + 3 # Compute gradients. y.backward() # Print out the gradients. print(x.grad) # x.grad = 2 print(w.grad) # w.grad = 1 print(b.grad) # b.grad = 1
# 来自:https://github.com/yunjey/pytorch-tutorial
不过你现在不需要羡慕了,如果你用TensorFlow 2.0,默认的积极模式(Eager Execution)和PyTorch如出一辙(你只需使用tensorflow.contrib.eager模块):
import tensorflow.contrib.eager as tfe
def f_cubed(x):
return x**3
grad = tfe.gradients_function(f_cubed)
grad(3.)[0].numpy()
值得强调的是,从TensorFlow 2.0开始,这种Eager Execution模式是默认的!也就是说,曾经我们在TensorFlow 1.0中的第一步构建流图graph,第二步让流图真正“流”起来的模式,现在默认不适用了。对于TensorFlow 1.0, 要随时打印一个变量值几乎不可能(因为一个Tensor只是一个内部变量):
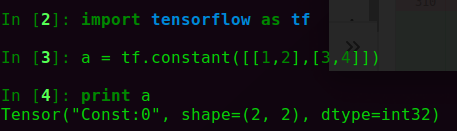 但是TensorFlow 2.0中,debug变得非常简单,一个tensor对象也可以随时用numpy.()方法转变成numpy对象:
但是TensorFlow 2.0中,debug变得非常简单,一个tensor对象也可以随时用numpy.()方法转变成numpy对象: 