
前言:
找工作时(IT行业),除了常见的软件开发以外,机器学习岗位也可以当作是一个选择,不少计算机方向的研究生都会接触这个,如果你的研究方向是机器学习/数据挖掘之类,且又对其非常感兴趣的话,可以考虑考虑该岗位,毕竟在机器智能没达到人类水平之前,机器学习可以作为一种重要手段,而随着科技的不断发展,相信这方面的人才需求也会越来越大。
纵观IT行业的招聘岗位,机器学习之类的岗位还是挺少的,国内大点的公司里百度,阿里,腾讯,网易,搜狐,华为(华为的岗位基本都是随机分配,机器学习等岗位基本面向的是博士)等会有相关职位,另外一些国内的中小型企业和外企也会招一小部分。当然了,其中大部分还是百度北京要人最多,上百人。阿里的算法岗位很大一部分也是搞机器学习相关的。
下面是在找机器学习岗位工作时,总结的常见机器学习算法(主要是一些常规分类器)大概流程和主要思想,希望对大家找机器学习岗位时有点帮助。实际上在面试过程中,懂这些算法的基本思想和大概流程是远远不够的,那些面试官往往问的都是一些公司内部业务中的课题,往往要求你不仅要懂得这些算法的理论过程,而且要非常熟悉怎样使用它,什么场合用它,算法的优缺点,以及调参经验等等。说白了,就是既要会点理论,也要会点应用,既要有点深度,也要有点广度,否则运气不好的话很容易就被刷掉,因为每个面试官爱好不同。
朴素贝叶斯:
有以下几个地方需要注意:
1. 如果给出的特征向量长度可能不同,这是需要归一化为统一长度的向量(这里以文本分类为例),比如说是句子单词的话,则长度为整个词汇量的长度,对应位置是该单词出现的次数。
2. 计算公式如下: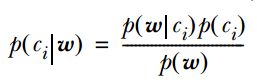
其中一项条件概率可以通过朴素贝叶斯条件独立展开。要注意一点就是 的计算方法, 而由朴素贝叶斯的前提假设可知:
的计算方法, 而由朴素贝叶斯的前提假设可知: 
因此一般有两种,一种是在类别为ci的那些样本集中,找到wj出现次数的总和,然后除以该样本的总和;第二种方法是类别为ci的那些样本集中,找到wj出现次数的总和,然后除以该样本中所有特征出现次数的总和。
3. 如果中的某一项为0,则其联合概率的乘积也可能为0,即2中公式的分子为0,为了避免这种现象出现,一般情况下会将这一项初始化为1,当然为了保证概率相等,分母应对应初始化为2(这里因为是2类,所以加2,如果是k类就需要加k,术语上叫做laplace光滑, 分母加k的原因是使之满足全概率公式)。
朴素贝叶斯的优点:
对小规模的数据表现很好,适合多分类任务,适合增量式训练。
缺点:
对输入数据的表达形式很敏感。 继续阅读机器学习 常见面试题 总结
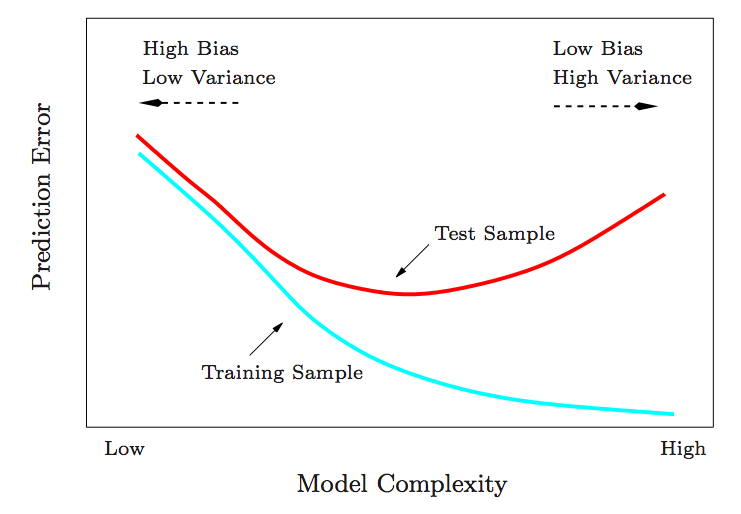
 代表了使用复杂模型
代表了使用复杂模型 情况下,数据集
情况下,数据集 被准确预测的概率和置信度(Evidence);
被准确预测的概率和置信度(Evidence); 代表了使用较简单模型
代表了使用较简单模型 情况下,数据集
情况下,数据集
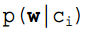{kind=link}