目前的迁移学习太粗浅, 归因于我们对表征的理解太粗浅. 但这是一个好方向, 如果我们能从”迁移学习”上升到”继承学习”, 任何模型都是”可继承”的, 不用担心今天的模型到了明天就毫无用处, 就像人类的基因一代代地演变, 是不是会有点意思 ? — David 9
太多初学者总是混淆迁移学习和预训练模型, David 9一直想为大家区分两者, 其实迁移学习和预训练并不难区分:
- 把模型的所有参数保存起来, 都可以宽泛地叫做预训练, 所以预训练比迁移学习宽泛的多. 我们并不设限预训练的保存模型未来的用处 (部署 or 继续优化 or 迁移学习)
- 把预训练的模型用在其他应用的训练可以称为迁移学习.
迁移学习(Transfer learning) 的原理相当简单:
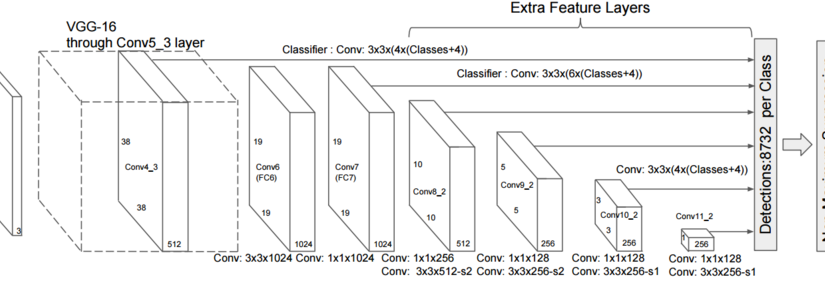
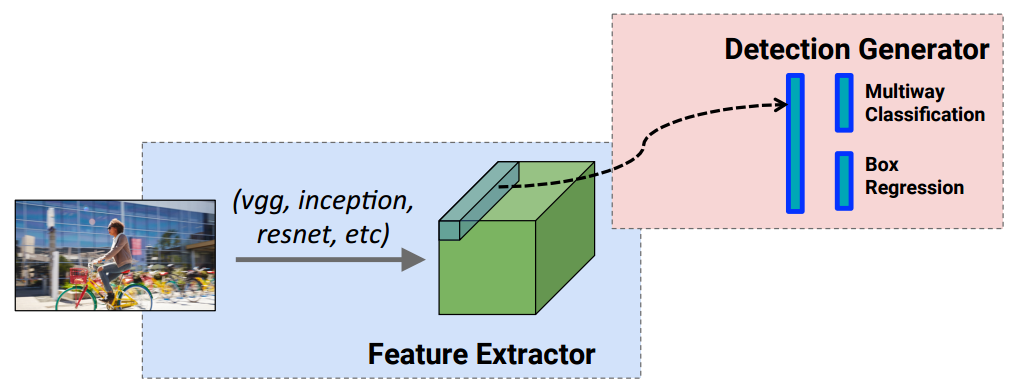
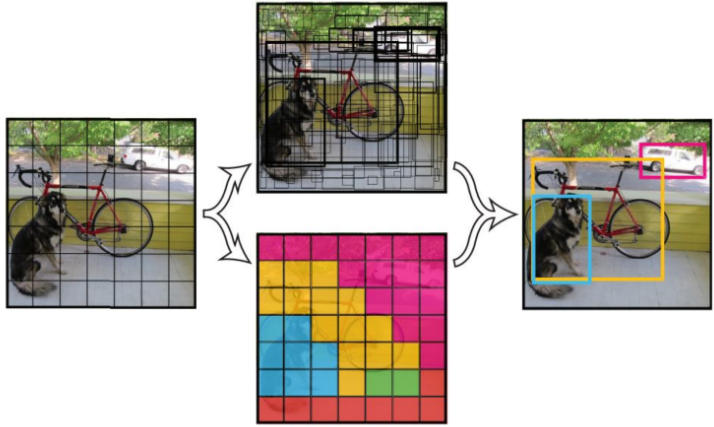
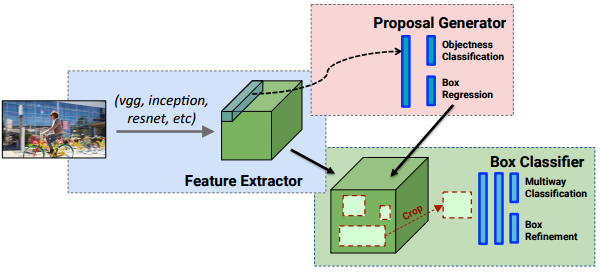
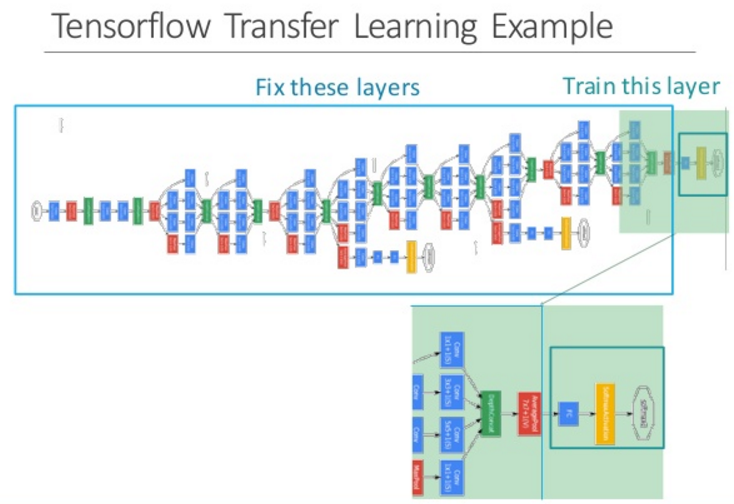 如上图, 复用之前预训练的复杂深度网络(第一行大蓝框), 我们复用倒数第二层对图像的输出特征作为新的训练输入.
如上图, 复用之前预训练的复杂深度网络(第一行大蓝框), 我们复用倒数第二层对图像的输出特征作为新的训练输入.
使用这个输入, 我们再训练一个迷你的浅层网络(第二行绿底网络), 就可以应用在其他领域. 继续阅读迁移学习101: Transfer learning, pretrained learning, fine tuning 代码与例程分析 源码实践