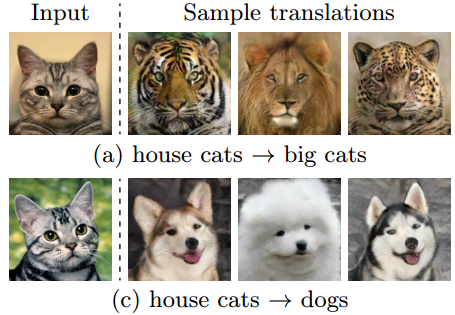
拥有什么,决定了你只能迷恋什么 — David 9
很大程度上,目前的芯片工艺和技术,决定了人类只能迷恋神经网络这样的方案(高于传统机器学习一个计算级别)。就像进入铁器时代,人们才能方便地砍伐森林、挖掘矿山、开垦土地(如果在青铜时代就别想了)。
在铁器时代,对铁器的改进很受欢迎;正如今年CVPR上大神Kaiming He和Xiaolong Wang 的文章试图改进神经网络工具去“开垦”视频分析 这片土地。
我们知道视频和图片的区别无非是多了时间的维度(time,视频的帧)。最直觉的做法是先用cnn,再用擅长时间序列的rnn;或者,直接用3D卷积去做。而实际情况是直接用3D卷积效果不是最好,于是有人用两个cnn去做(一个cnn分析时间,一个cnn分析空间),或者另外用一个分析轨迹(trajectories)的模块去加强时空感。
而非局部(non-local) 模块把非局部感受野的信息提取操作做成一个神经网络模块,方便了端到端的视频分析:
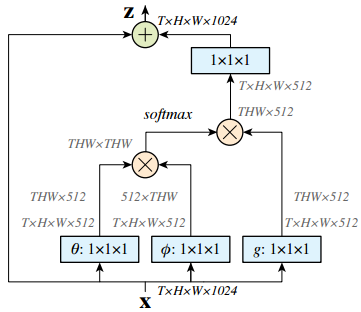
这个模块输入x可以理解为32帧的视频(32张图片帧数 T=32,长宽为H×W),输出z也是H×W大小的特征图。有没有注意到最左端的箭头是一个跳层连接?没错,non-local模块就是把视频额外的时空信息提取作为一个残差操作,这样整个模块可以任意插入到一个残差网络resnet中: 继续阅读CVPR2018精选#2: 视频分析的非局部(non-local) 神经网络模块,CMU与Facebook AI研究室视频分类识别新贡献