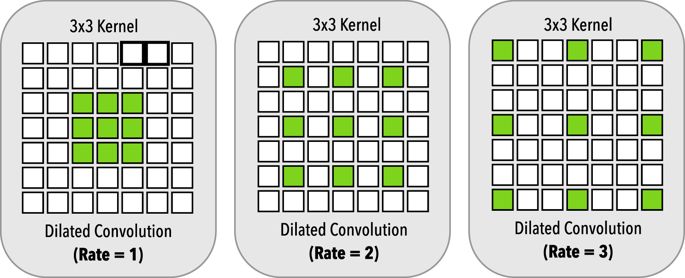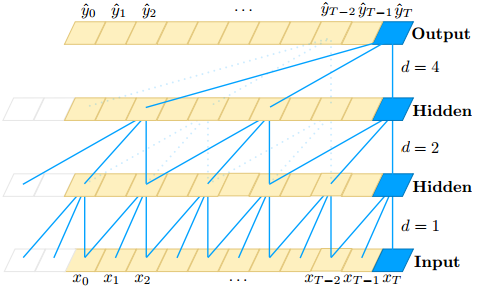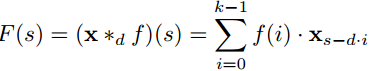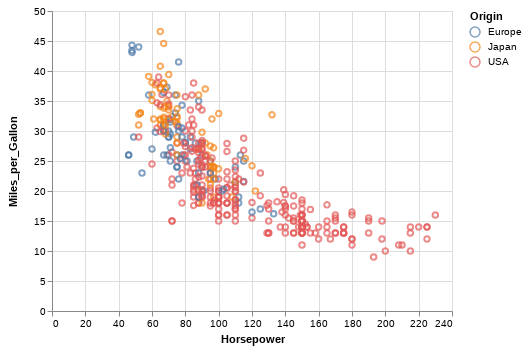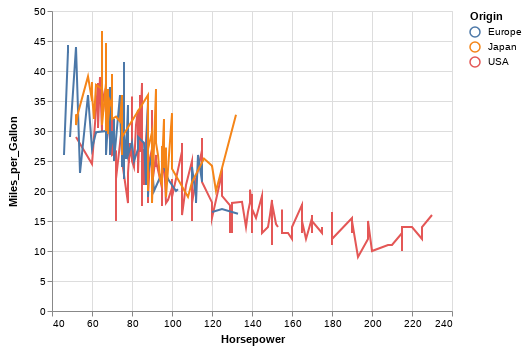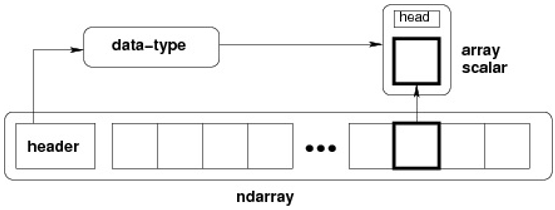
软件演进和生物进化一样,没人可以预测下一步走向哪里,我们只知道,它需要人类的脑力和贪婪去喂养 — David 9
谁也没有想到30年前Guido写的Python因为通俗易用、丰富的联网支持,变为现在数据科学家最喜爱的工具语言之一。甚至小小的代数计算库Numpy会涌现如此多的扩展库和矛盾。
有人认为,长颈鹿之所以进化时如此过度关注脖子长度(其实适当高度就足够了),只是因为母长颈鹿认为雄长颈鹿脖子越长越有性魅力(种内竞争)。
软件进化也类似,人类社区中那些勤劳的开发者努力让Numpy支持各种场景(多核分布式、GPU利用、稀疏处理和Autograd ),解决各种矛盾(ndarray不兼容,numpy插件系统不到位)。但是,他们的汗水都是基于Python这个“种族”进化的,种内竞争激烈不一定能保证软件的发展方向好 。。。
扯远了。。今天还是想盘点高阶Numpy扩展库与API ,毕竟许多人不满足于基础的numpy代数计算。比如下面这些场景(重写库):
- CuPy: 实现Numpy有的API ,保证所有计算可以在CUDA GPU上加速
- Sparse: 对于稀疏的ndarray(许多元素是0的情况), 重写实现Numpy的API(更高效)
- Dask array: 对于多核或者多机器的工作站,为了可以分布式或者多核,又重写Numpy API ,所以有了这个库
最简单的例子大概是这样的:
import numpy as np x = np.random.random((2,3)) # 在一个cpu上跑 y = x.T.dot(np.log(x) + 1) z = y - y.mean(axis=0) print(z[:5]) import cupy as cp x = cp.random.random((2,3)) # 在GPU上跑 y = x.T.dot(cp.log(x) + 1) z = y - y.mean() print(z[:5].get()) import dask.array as da x = da.random.random((2,3)) # 在许多cpu上跑 y = x.T.dot(da.log(x) + 1) z = y - y.mean(axis=0) print(z[:5].compute())
默默妈卖批,这帮人就不知道合作一下合成一个库吗? 继续阅读高阶Numpy扩展库与API盘点:在ndarray上直接进行多核分布式、GPU利用、稀疏处理和自动求导,那些你不知道的ndarray扩展操作