如果“你所能告诉我的,只是你想表达的十分之一”,那么“表达”和接受“表达”的效率,也许是智能重要组成之一 — David 9
我们知道目前的AI无法表达自己,甚至,连接受“表达”的能力也相当有限。在NLP(自然语言)领域比其他领域更滞后。从word2vec词向量到ELMo,再到2018年谷歌的BERT系列模型,深度神经网络在NLP领域中“半推半就”达到一个有共识的高度:
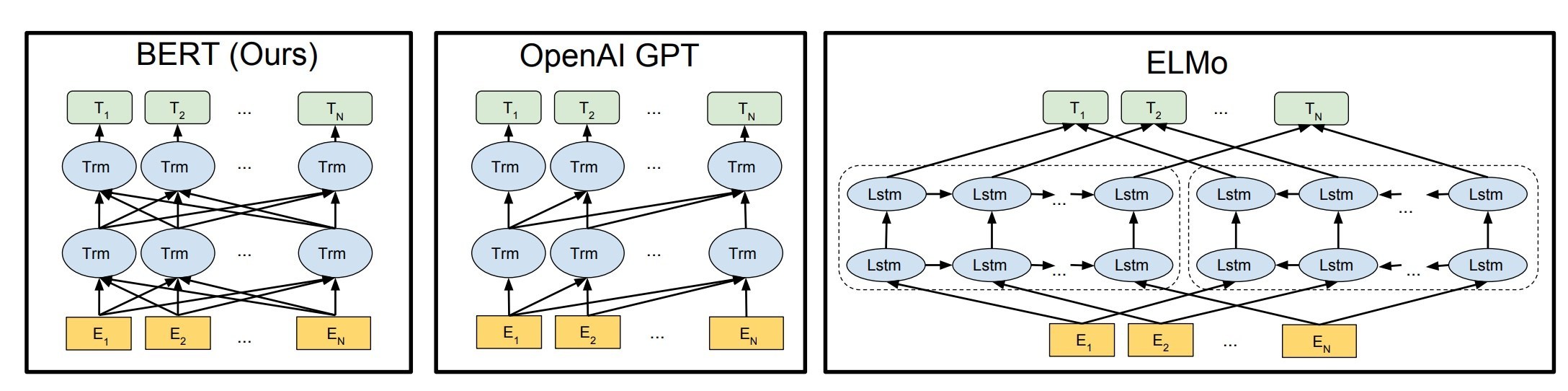
即使经过这样一个漫长的过程,BERT系列模型还是需要在预定domain域上事先做大规模预训练,才能在下游任务上表现更好:
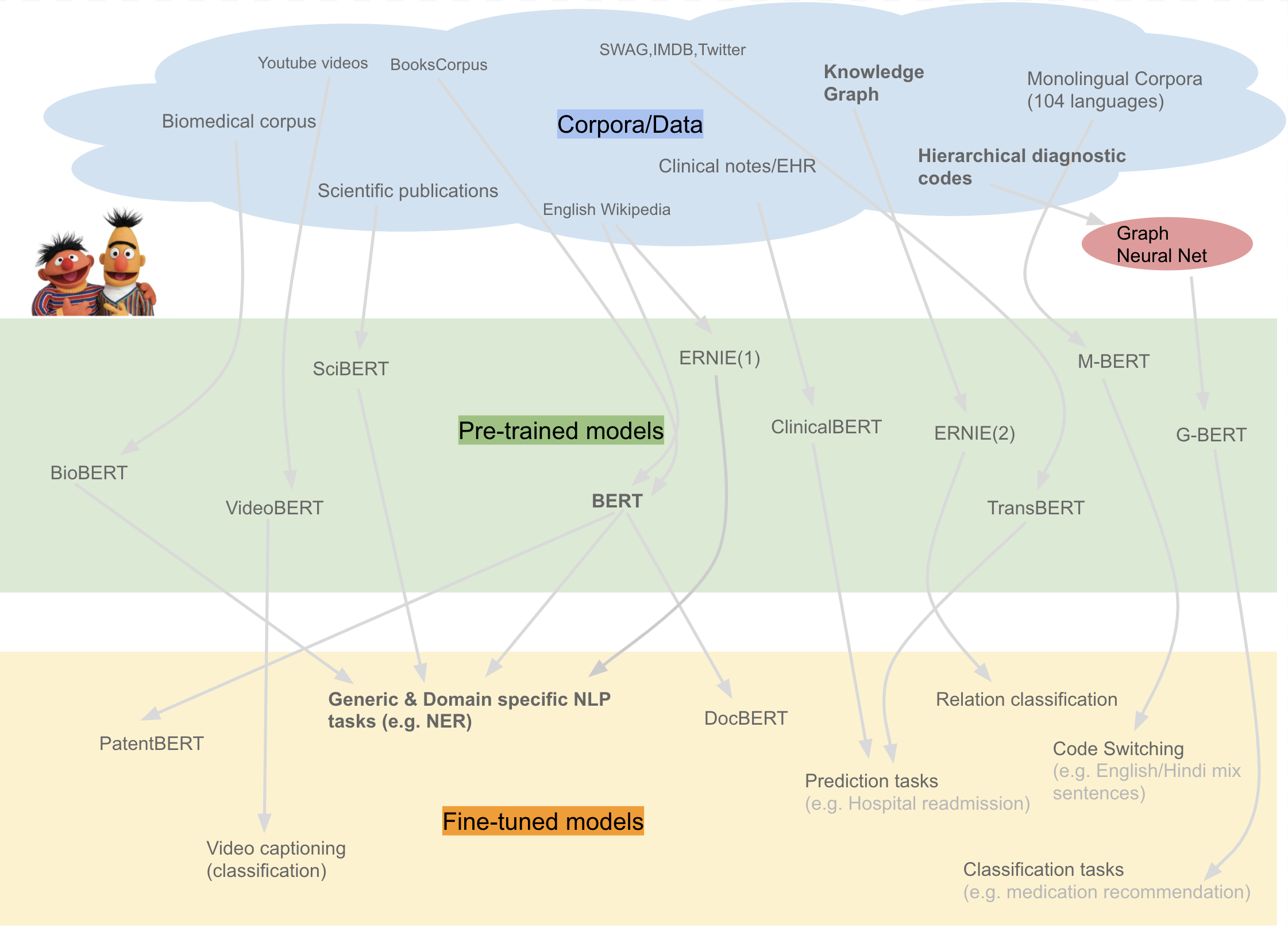
“大规模预训练”,“更宽深层双向encoding”,“带MASK的无监督训练”,“注意力机制”,“fine-tuned模型”,对BERT有一些深入了解的朋友一定对以上这些词不陌生。是的这些是BERT训练要素。
但是BERT有效,是因为在目前大数据和算力的条件下,不得已只能使用这种方式超越前任算法。这种方式的好处很明显:
1. 多头的注意力机制和双向encoding让BERT的无监督训练更有效,并且使得BERT可以构造更宽的深度模型:

2. 把特定任务的模型fine-tune放到后面去做,增大整个模型的灵活性。如果你能拿到较好的预训练模型,甚至再用一个简单的logistic回归就能fine-tune出一个较好的任务模型。
3. BERT无监督(自监督)的预训练,给了其他连续型数据问题很多想象力。所谓连续型数据问题,指那些像语言,音频,视频等(如果任意删除其中一段,在语义上就显得不连贯)。这种数据结合BERT模型可以做一些有意思事情,如VideoBERT, 就是通过把字幕和视频拼接,作为一个新的连续型BERT模型(用来自动生成字幕): 继续阅读回顾BERT优势与劣势:深入理解这些无监督怪兽,及其前景展望,GPT,BERT,VideoBERT