如果抽象能力足够强, 世间一切关系, 是否都能用距离(Distance)表达? — David 9
接着上一讲, 今天是David 9 的第二篇”NIPS 2016论文精选”: Supervised Word Mover’s Distance (可监督的词移距离). 需要一些nlp自然语言处理基础, 不过相信David 9的直白语言可以把这篇论文讲清晰.
首先, 整篇论文的最大贡献是: 为WMD(词移距离) 提出一种可监督训练的方案, 作者认为原来的WMD距离算法不能把有用的分类信息考虑进去, 这篇论文可以填这个坑 !
但是, 究竟什么是Word Mover’s Distance(WMD) ? 这还得从word2vec说起:
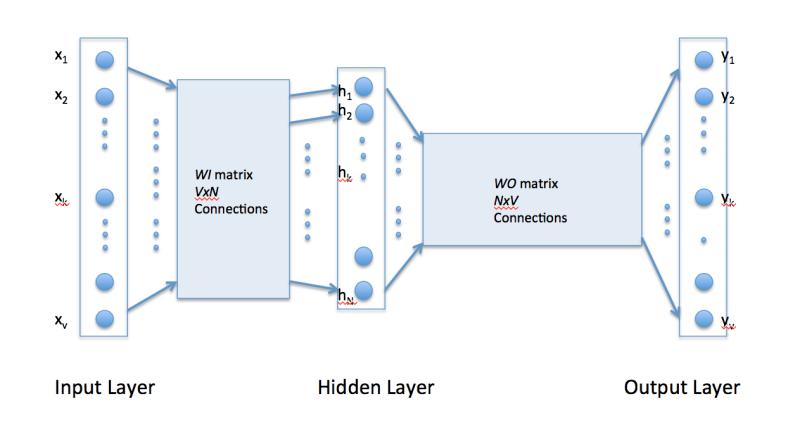
还记得这张图吧? 在 “究竟什么是Word2vec ?” 这篇文章中我们谈到过word2vec其实是把一切word单词映射(压缩)到一个一个隐含的词向量(这里的h层). 在这个向量空间中, 我们可以做一些有意思的事情:
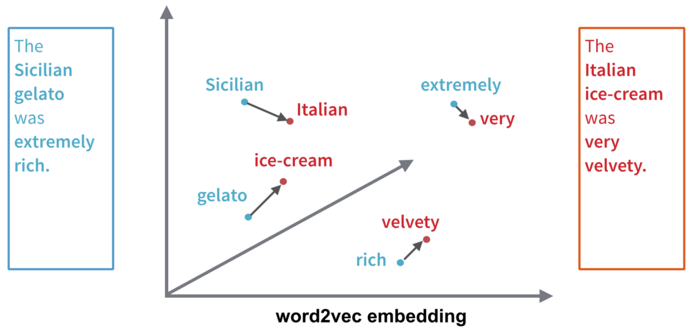
比如我们很容易知道, 空间中 Sicilian(西西里岛人) 和 Italian(意大利人) 距离上很接近, gelato(意式冰激凌)和ice-cream(冰激凌)在距离上也很接近.
Word Mover’s Distance(WMD) 词移距离正是基于word2vec.
WMD考虑文章间的距离而不是词间的距离, 上图左边文章说的是: The Sicilian gelato was extremely rich(西西里岛人的意式冰激凌很美味) , 右边文章说的是: The Italian ice-cream was very velvety(意大利人的冰激凌很嫩滑). 要从左边文章转换到右边文章, 我们需要的是图中转移箭头代表的转移向量构成的转移矩阵 ![]() 所以, 两篇文章的WMD距离为:
所以, 两篇文章的WMD距离为:
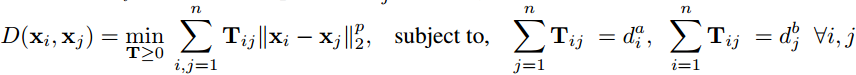
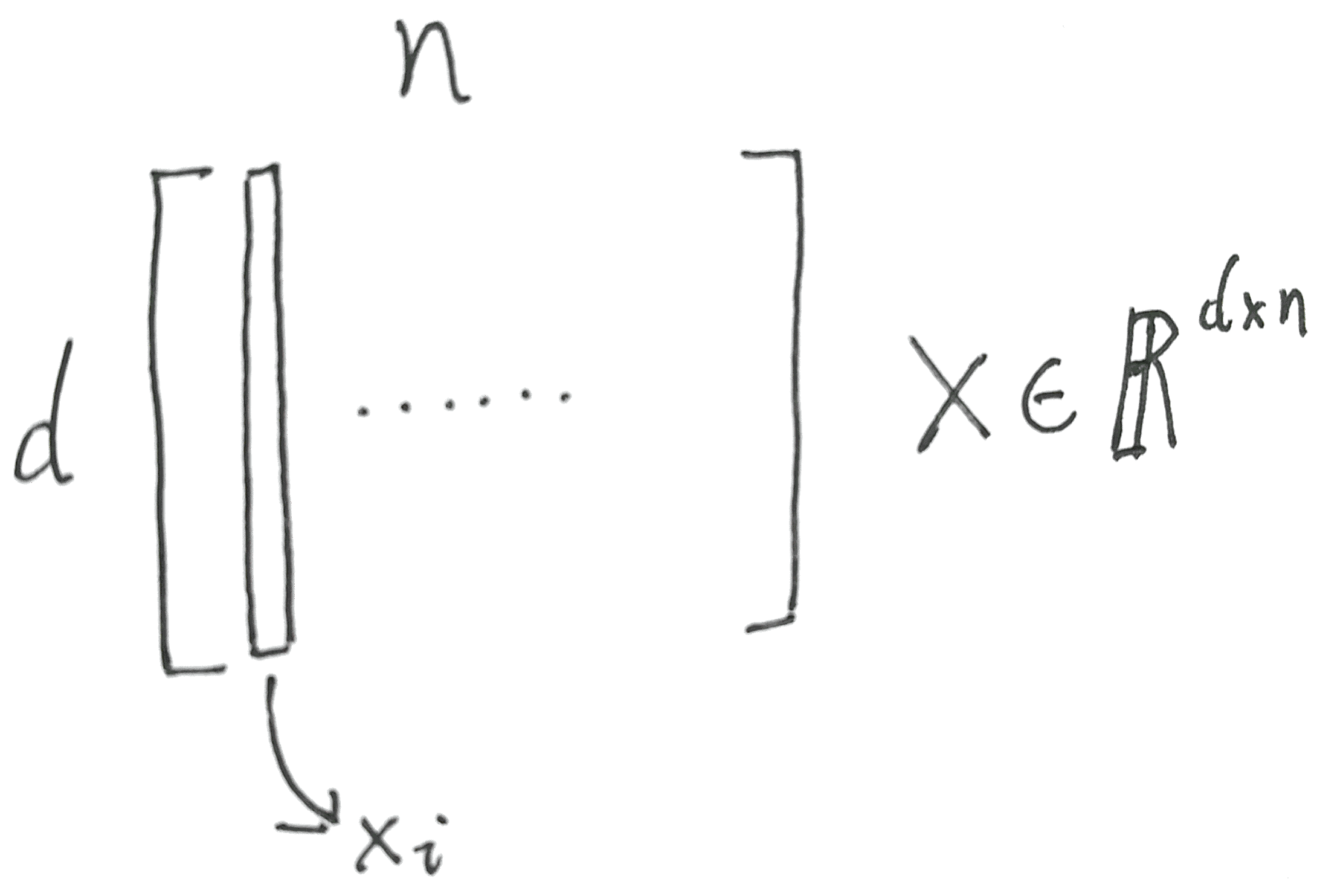
这里的xi其实是被word2vec压缩过的d维的隐藏层词向量.
D(xi, xj)代表两篇文章最短距离的实际意义是: 所有文档a中单词转移到文档b中单词的最短总距离. 换句话说, 两篇文档总距离中的每个单词距离分两部分计算:
1. 单词间的word2vec距离![]()
2. 单词xi放到另一篇文档中应该转换为单词xj的权重:
![]()
比如Sicilian真的很应该转换为Italian, 所以在转换时我们应该给Italian更大权重.
我们理解了WMD距离, 那么问题来了, 学习这个权重矩阵用来聚类虽好(告诉我们哪些文档比较相近), 但是, 用来分类却很差!
为什么? 因为一些文章虽然近义词很多, 但是表达的不是一个语义和主题. 比如: I love playing football 和 I like playing piano . 虽然看起来句式差不多, 可能会归为同类, 但是如果打标签时如果是”运动”和”艺术”两类, 显然就不能用WMD直接分类了. 因为, WMD没有加入 football和”运动” 是强相关的信息.
所以, 论文给出的解决方案就是在WMD距离中加入可以训练类别权重的功能:
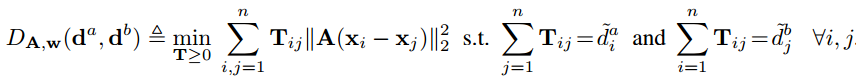
这里的di加入了类别权重wi:
![]()
单词间距离也要进行调整(单词间距离也因为类别不同需要调整距离), 加入训练参数矩阵A.
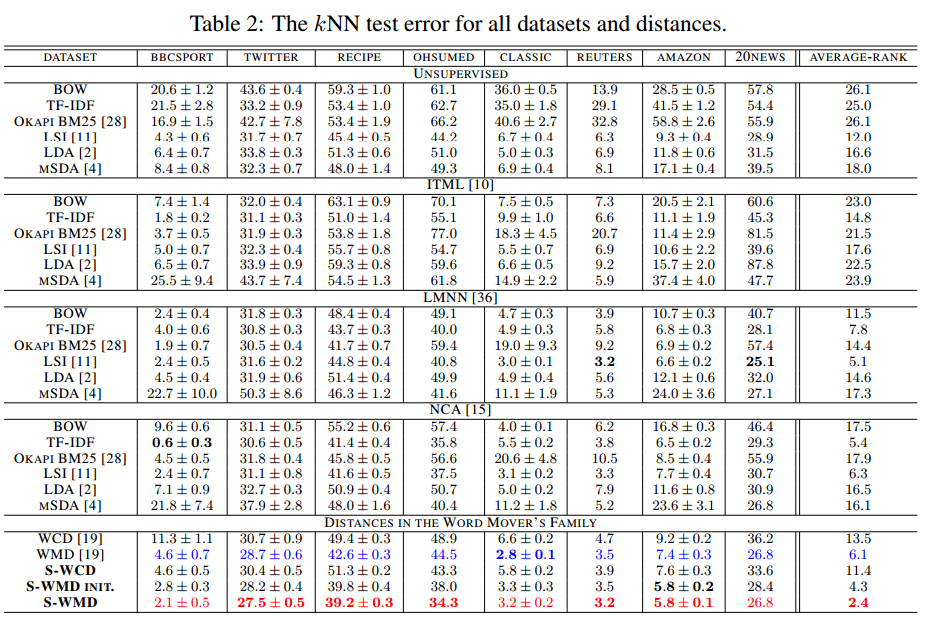
最后, 看一下实验效果, S-WMD正是本论文提出的对应算法名:


参考文献:
- http://papers.nips.cc/paper/6139-supervised-word-movers-distance.pdf
- https://en.wikipedia.org/wiki/Conference_on_Neural_Information_Processing_Systems
- https://nips.cc/Conferences/2016/Schedule?type=Poster
- http://tech.opentable.com/2015/08/11/navigating-themes-in-restaurant-reviews-with-word-movers-distance/
- http://vene.ro/blog/word-movers-distance-in-python.html
本文章属于“David 9的博客”原创,如需转载,请联系微信: david9ml,或邮箱:yanchao727@gmail.com
David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024
> 我们理解了WMD距离, 那么问题来了, 学习这个权重矩阵用来聚类虽好(告诉我们哪些文档比较相近), 但是, 用来分类却很差!
这个地方用“学习”这个词是否不妥,WDM只是计算两句话的距离,计算完没有重用也没生成模型,是否用“计算”更合适?
不只是计算,我的理解是其中Tij这个矩阵是要训练的,word2vec是需要训练的,而该论文就是基于word2vec的。
想请教一下作者,矩阵Tij要怎么得到
训练得到