
你曾经有没有根据声音预测人的面容?或者,看一个陌生人一面,你在心里其实已经预测了他说话的声音?
今年CVPR2019上的Speech2Face模型就试图还原这一过程。虽然David认为模型上没有什么新意,但是这篇文章的一些实验结论很有意思。
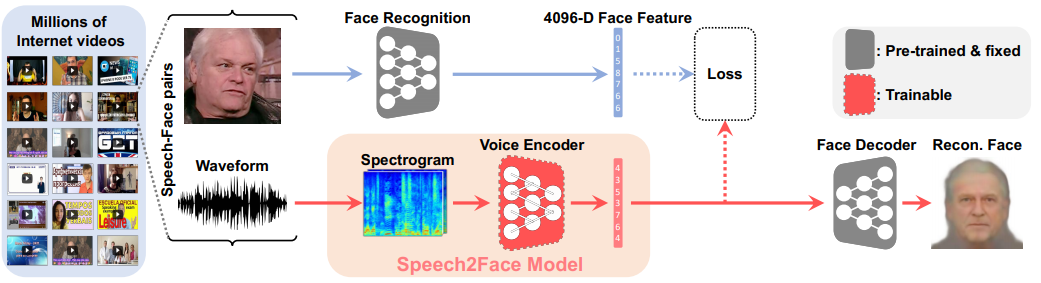
模型上中规中矩,先预训练Face encoder和decoder(灰色块部分),让模型可以压缩脸部特征并根据脸部特征向量还原出图像。然后,引入Voice Encoder,把音频一样压缩到特征向量(红色块部分),这个音频特征向量应该可以用来很好地预测对应的人脸,如果预测不好,就应该增加Loss,反向反馈训练。
了解原理之后,最有意思的其实是一些统计实验结论,官方的总结可以看如下链接:

The following two tabs change content below.




David 9
邮箱:yanchao727@gmail.com
微信: david9ml
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024