人类日常行为中自觉或不自觉地总结抽象的”套路”, 以便将来在相同的情况下使用. 分层的增强学习正是研究了在较高的抽象任务中, 应该如何看待以前总结的”套路”, 并且如何在较低层的行为中使用它们. — David 9
正如我们之前提到过, 深度神经网络的迅速发展, 不会阻碍类似增强学习这样的高层学习框架发展, 而是会成为高层框架的重要底层支撑.
今年ICML最佳论文提名中的一篇(Modular Multitask Reinforcement Learning with Policy Sketches), 正是属于分层增强学习: 用”策略草稿“进行模块化的多任务增强学习.
说的通俗一点, 就是教会神经网络学习在各个不同的任务中总结通用的”套路”(或者说策略草稿,行为序列):
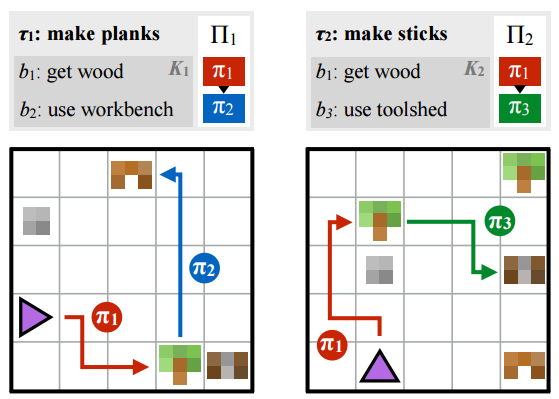
上图左右两图, 分别代表两个高层任务(“制作木板”(make planks) 和 “制作木棍”(make sticks)). 事实上, 这两个高层任务的完成, 都需要一个子策略π1的必要条件, 即 : 我们需要首先拿到木材 !
对于传统的分层强化学习, 更多的是类似马尔科夫链的推导过程:
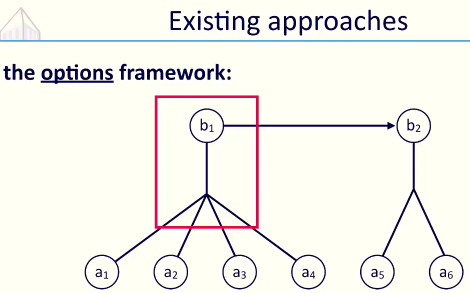
b1, b2 是被符号化的高层指令(如刚才说的”制作木板”或”制作木棍”), 而底层的a1到a6就是单个的行为(比如”砍树”, “削木棍”等等). 如何把高级指令下的类似”套路”(行为)总结出来? 传统方法可以为这些特别的行为特意加上更多的共享回报:
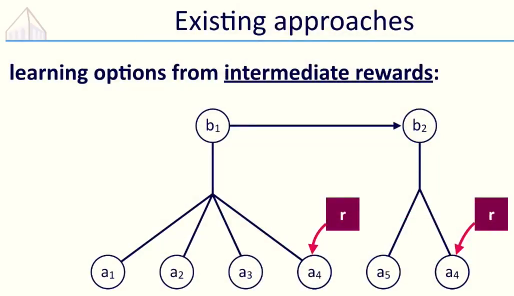 通过共享权重r 体现高层指令下策略的共性.
通过共享权重r 体现高层指令下策略的共性.
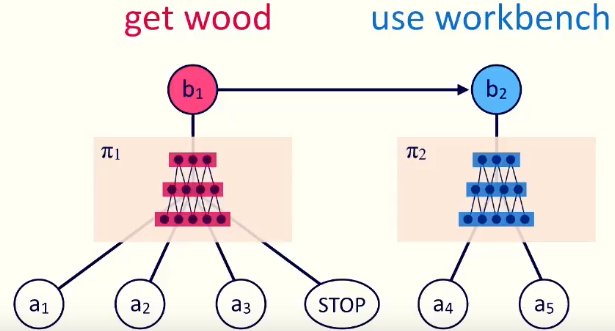
而作者提出的方法, 把下层的a1-a4这样的行为序列看成”策略草稿”, 这样的草稿通过一个神经网络生成:
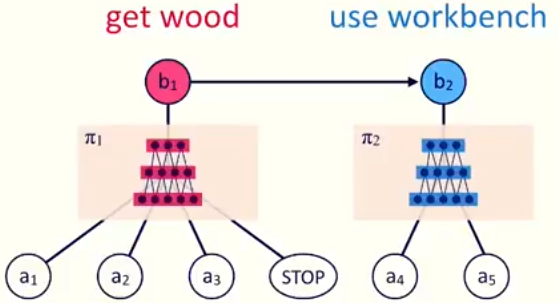
在激活特别的策略(如π1)时, 神经网络就会通过当前状态,生成特别的行为序列, 直到生成STOP行为, 才停止生成行为, 并进入下一个策略的激活(π2) .
进一步, 每个神经网络对应一个子策略, 如子策略π1, 输入是一系列的当前环境状态(s1-s4), 输出是这些环境下应该采取的行为(a1-a4). 直到STOP为止.
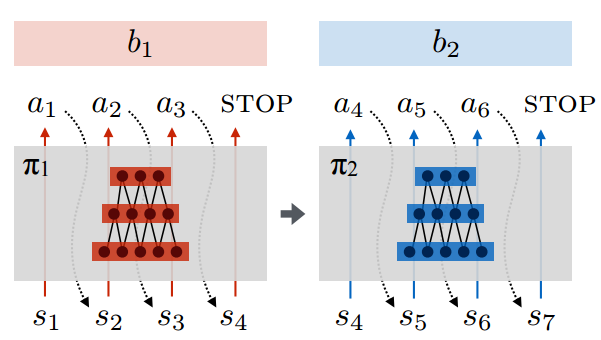
所以论文实验必须维护多个神经网络(代表多个子策略), 那如何训练这些神经网络呢 ?
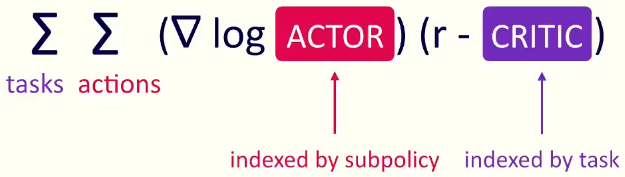
毫无疑问, 低层行为的回报值和高层任务的回报值都要兼顾:

上式正是模型更新参数的关键, 分为两部分: 前半部考虑当前使用的子策略的因素;
后半部分考虑当前策略行为在某个高层任务的回报:

此处的b 正是对高层任务回报值的考虑, 如果b偏大, 说明当前行为多高层任务其实没有太大价值, 所以适当降低回报值.
即, 前半部分是对子策略的考虑, 后半部分是对高层任务的考虑:
 最后实验部分, 与其他共享策略的算法相比, 本论文的算法在平均回报率上达到最高:
最后实验部分, 与其他共享策略的算法相比, 本论文的算法在平均回报率上达到最高:
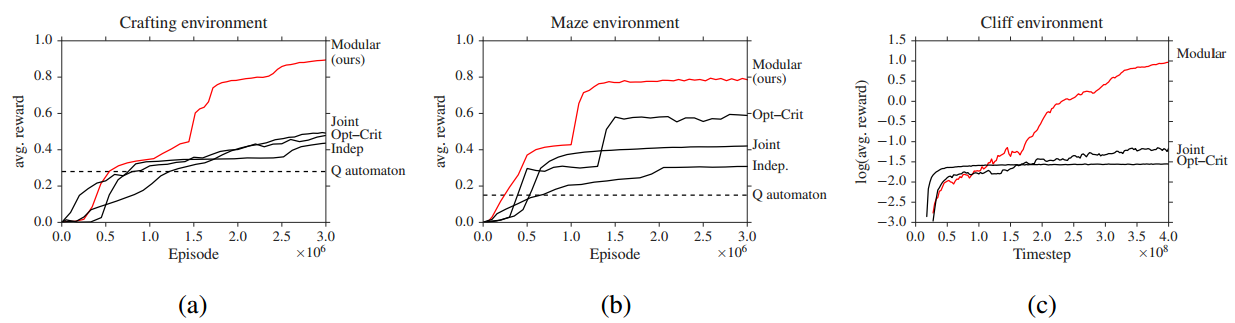 David 9认为该算法优势之一是其灵活性, 较一般的任务间共享策略的方法, “策略草稿”在生成策略行为和上层任务的迁移上更加灵活. 另外, 引入的神经网络模块使得泛化能力有所提高, 对于稀疏状态下的情况也可以有较好的行为计划.
David 9认为该算法优势之一是其灵活性, 较一般的任务间共享策略的方法, “策略草稿”在生成策略行为和上层任务的迁移上更加灵活. 另外, 引入的神经网络模块使得泛化能力有所提高, 对于稀疏状态下的情况也可以有较好的行为计划.
参考文献:
- Modular Multitask Reinforcement Learning with Policy Sketches
- https://www.youtube.com/watch?v=NRIcDEB64x8
- https://github.com/jacobandreas/psketch
本文采用署名 – 非商业性使用 – 禁止演绎 3.0 中国大陆许可协议进行许可。著作权属于“David 9的博客”原创,如需转载,请联系微信: david9ml,或邮箱:yanchao727@gmail.com
或直接扫二维码:

David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024