
如果你想成为大师,是先理解大师做法的底层思路,再自己根据这些底层思路采取行动? 还是先模仿大师行为,再慢慢推敲大师的底层思路?或许本质上,两种方法是一样的。 — David 9
聊到强人工智能,许多人无疑会提到RL (增强学习) 。事实上,RL和MDP(马尔科夫决策过程) 都可以归为策略学习算法的范畴,而策略学习的大家庭远远不只有RL和MDP:
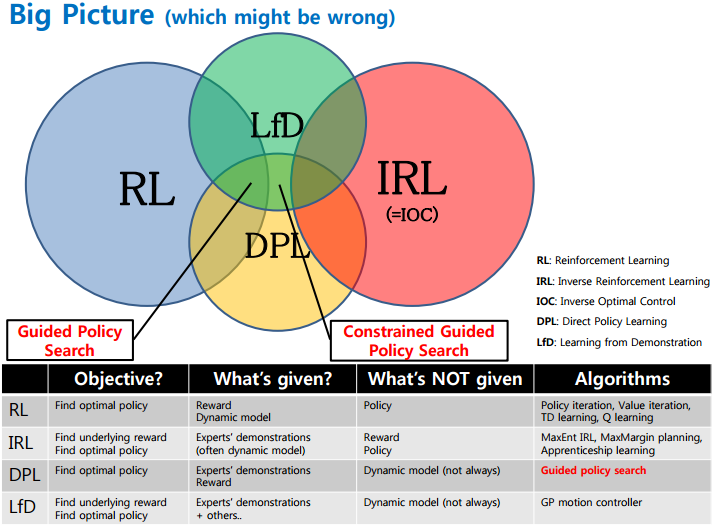
我们熟知的RL是给出行为reward(回报)的,最常见的两种RL如下:
1. 可以先假设一个价值函数(value function)然后不断通过reward来学习更新使得这个价值函数收敛。价值迭代value iteration算法和策略policy iteration算法就是其中两个算法(参考:what-is-the-difference-between-value-iteration-and-policy-iteration)。之前David 9也提到过价值迭代:NIPS 2016论文精选#1—Value Iteration Networks 价值迭代网络)
2. 可以先假设一个policy(没有价值函数 ),从这个policy抽样一连串的行为,
得知这些行为的reward后,我们就可以由此更新policy的参数。这就是DPL(Direct Policy Learning)(参考:Whats-the-difference-between-policy-iteration-and-policy-search)
以上两种方法最后都是为了学习到一个好的policy(策略,即状态->行为的映射),所以这些函数都可以归为策略学习算法。
除了这些,还有一种更有意思策略学习问题:如果没有reward(回报)的给出,只有专家(或者说大师)的一系列行为记录,是否能让模型模仿学习到大师的级别?(当然就目前的技术,我们需要大量的大师行为记录)。
这种类似模仿学习的问题就叫IRL(Inverse Reinforcement Learning或者逆向强化学习)。所以请再仔细看一下这些方法的区别:
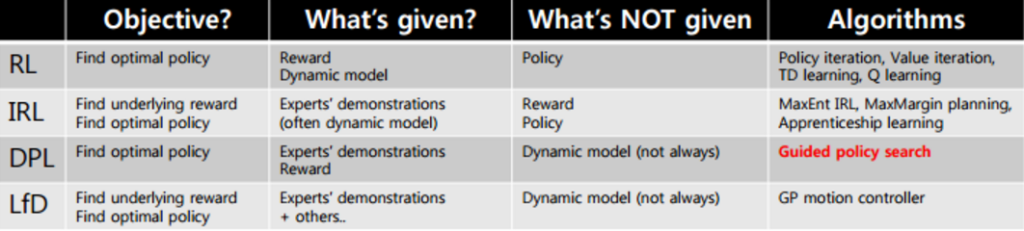
了解了这些大类,我们在回到RL,现在进入我们的正题TRPO算法(Trust Region Policy Optimization)。

David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024