
人类在做其他看似不相关的事情时,会给手头的任务带来灵感; 模型也应如此,让它在训练时做其他任务,会对它的实际预测带来好处(正则约束) — David 9
多任务模型David不是第一次讲了,但是之前涉及的是强化学习或自然语言领域。在视觉领域,多任务学习就更有意思了。自动驾驶是该领域的常见应用,不但要求准确率99%+,极低延时,而且是一个开阔的“无限游戏”,正如特斯拉AI负责人Andrej Karpathy在ICML2019发言上提到的,其复杂性是多方面的,
遇到的车况可能很复杂:

摄像头的视觉角度也很复杂(8个方向):

更复杂的是,自动驾驶天生就是多任务的:
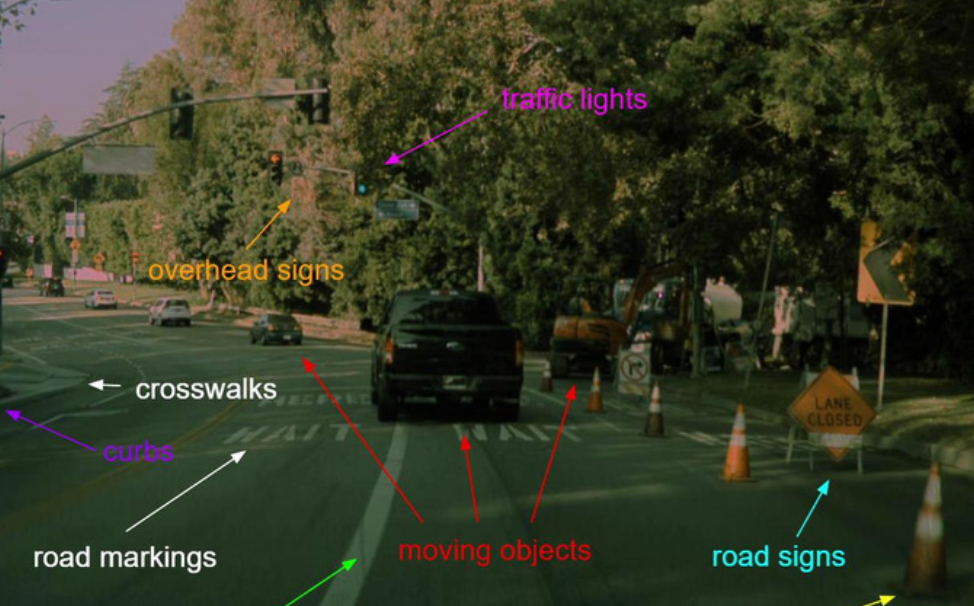
在你开车时,你的眼睛和大脑要同时分析移动的车辆,静态的路灯,斑马线,路标,警示牌,等等。。。甚至loss函数的设计都是复杂的,因为一些任务就是比一些任务更重要(我们要重点关注突然闯红灯的行人)
要适应如此复杂多变的环境并且要求实时导航,如何去建模真的很有挑战性。首先,你不可能对每个任务都建一个模型:
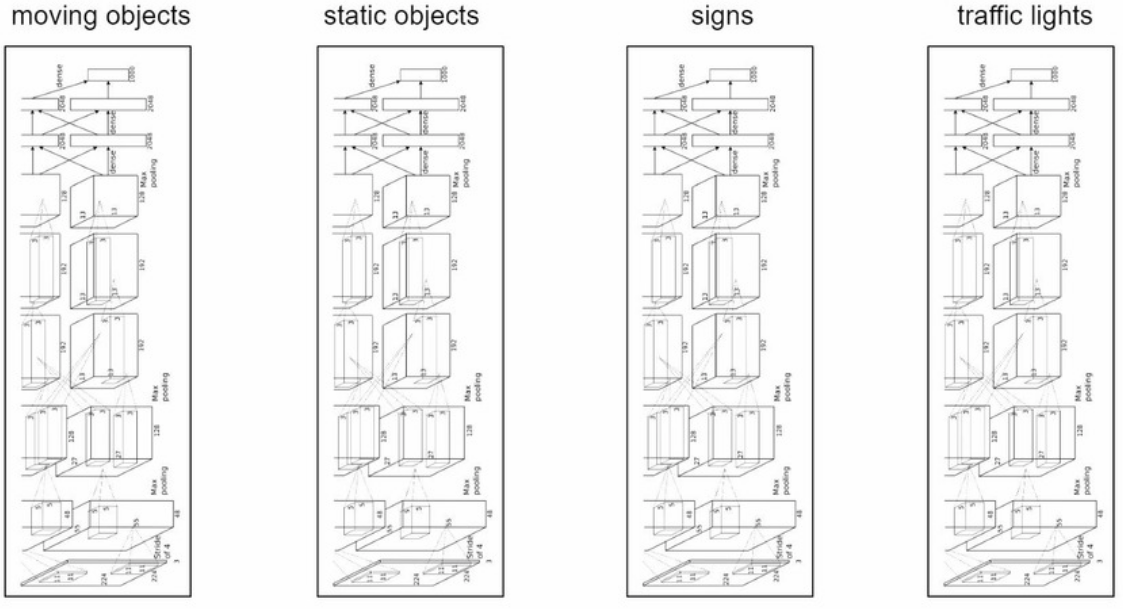
这样哪怕可行开销也太大(除非你想多送用户几块gpu或硬件资源)。另一个极端是所有任务都合并为一个模型:
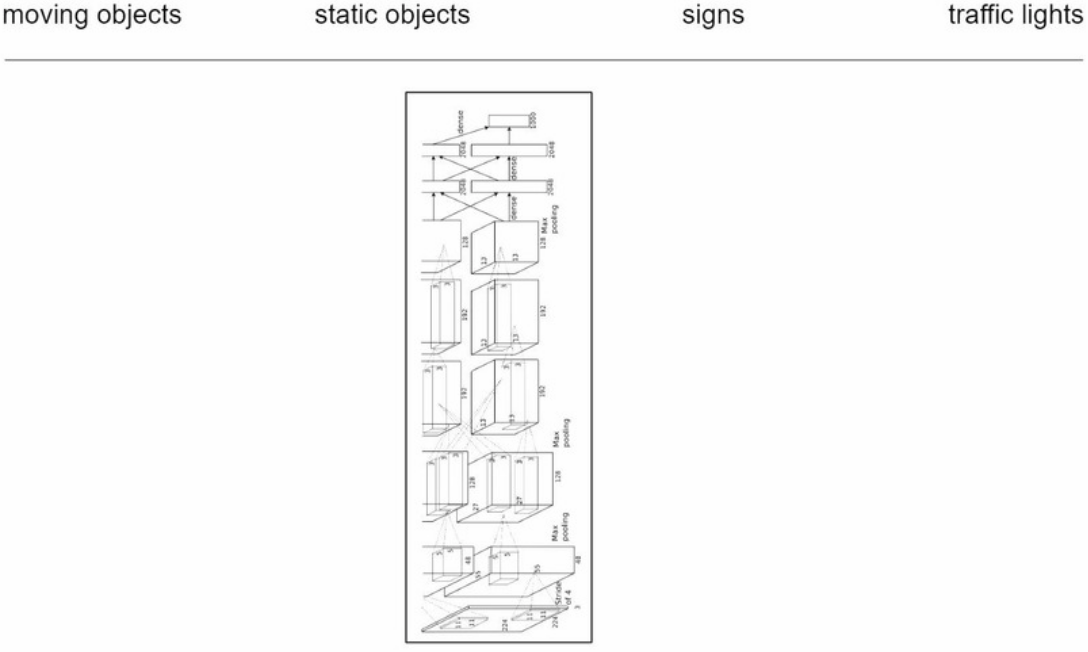
这也不太现实,研究automl的许多论文(Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation)已经侧面证明,哪怕是单个任务,模型搜索也是一件不容易的事:
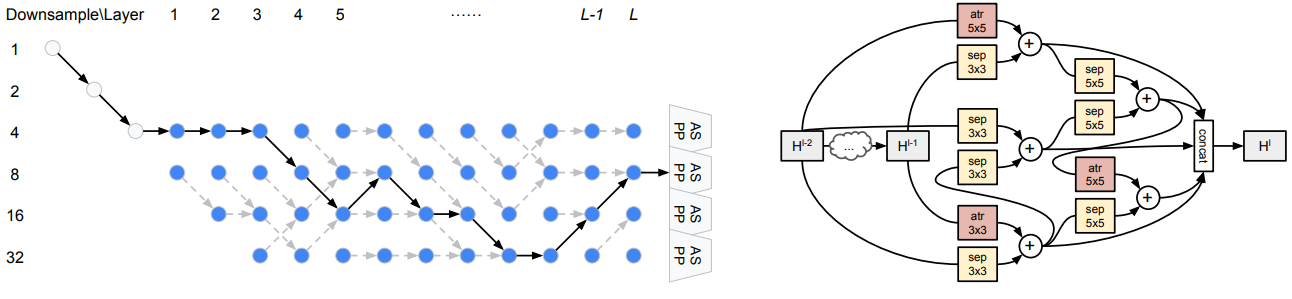
那么特斯拉内部是如何处理多任务学习的 ?David觉得如下3点特别有意思:
第一,特斯拉自动驾驶实际是要用一个折中的多任务模型搜索方案,方案借鉴这篇论文:

The following two tabs change content below.




David 9
邮箱:yanchao727@gmail.com
微信: david9ml
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024