召回率和准确率就像你去赌场要同时带着“票子”和“运气” — David 9
在机器学习面试中,经常会问道“召回率”和“准确率”的区别 。 其实,就像你去赌场下注一样,如果你“票子”很多,可以把钱分摊在不同的赌注上,总有一个赌注会猜对,当你猜对了,就是一次“召回”了; 而“准确率”不关注你下多少注,好似你在赌场碰“运气”,下注越多,越能看出你今天的“运气”。
因此,你猜的次数越多自然有较大的召回,当然最好的情况是,你猜测很少次数就能召回所有。
计算召回率(Recall) 和 精确率(Precision) 时,人们一般会先搬出TP(True positive),TN(True negative),FP(False positive),FN(False negative )的概念:
Condition: A Not A
Test says “A” True positive | False positive
----------------------------------
Test says “Not A” False negative | True negative
然后给出公式:
召回率 Recall = TP / (TP + FN)
准确率 Precision = TP / (TP + FP)
事实上,不用硬背公式。两者的抽样方式就很不同: 召回率的抽样是每次取同一标签中的一个样本,如果预测正确就计一分;准确率的抽样是每次取你已预测为同一类别的一个样本,如果预测正确就计一分。这里一个关键点是:召回率是从数据集的同一标签的样本抽样;而准确率是从已经预测为同一类别的样本抽样。召回率和准确率都可以只针对一个类别。
所以当只看top-1的预测时,因为只抽样同一标签的样本,还没有完全召回,所以召回率比较低;而准确率上,top-1以较大的置信度预测一个类别,该类别的准确率较高:
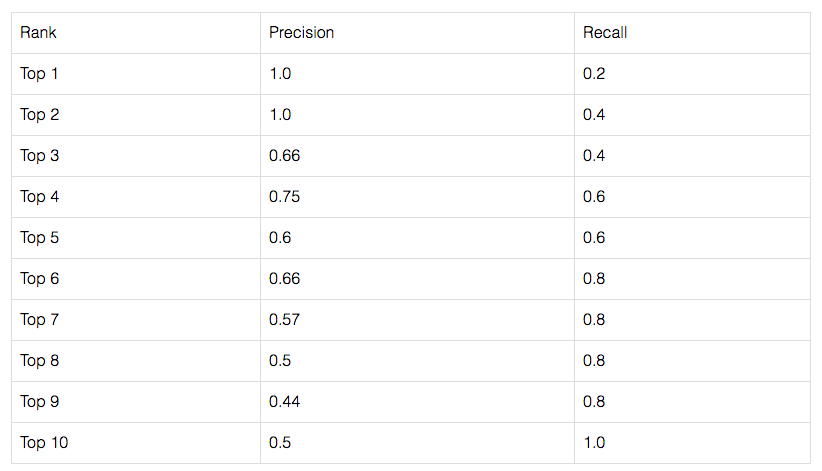
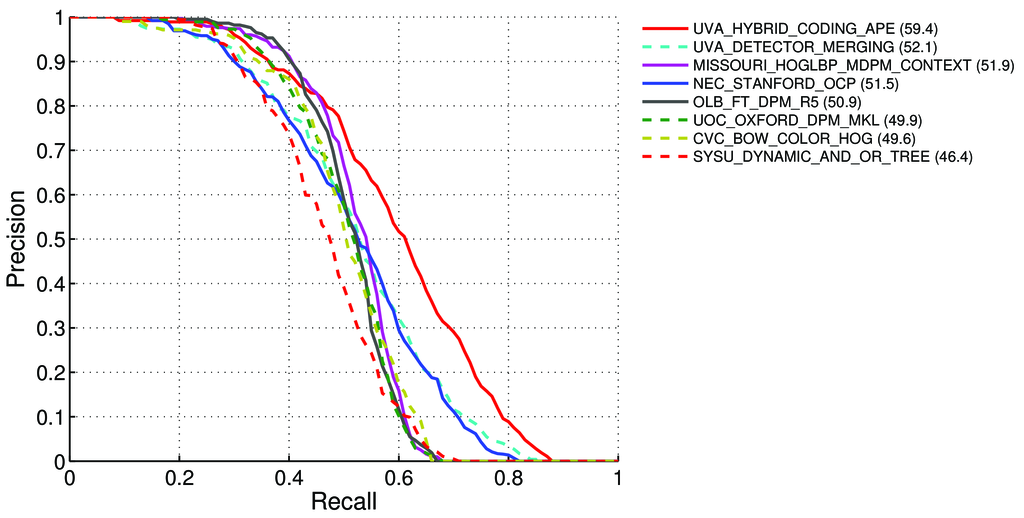
事实上,如果从top-1到top-10排序来看,召回率是越来越大,最后到1.0(因为top-10预测时,猜10次总能猜对这个类别,并把它召回);准确率是越来越小的,因为top-10的时候是模型置信度最低的时候,猜准该类别的几率较小 。下面是recall-precision曲线:
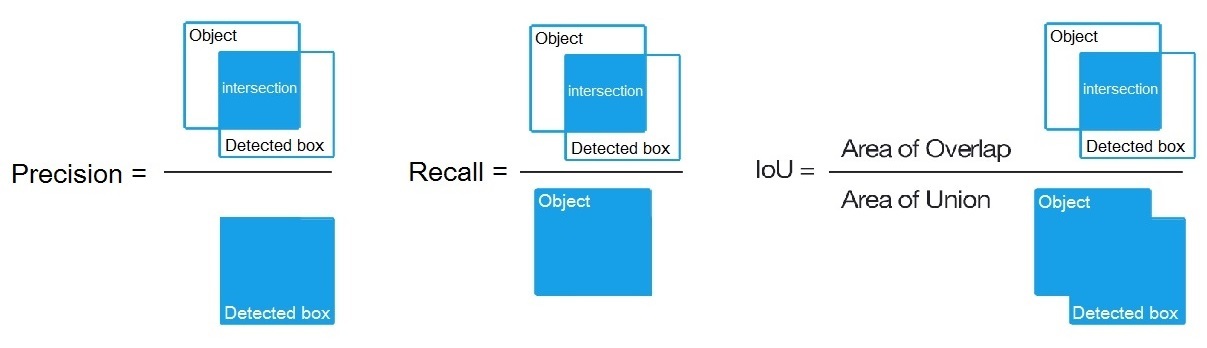
在机器视觉目标检测领域也是一样的,recall和precision只是分母抽样的方式不同:
为了更好地评估一个模型的准确率,人们提出的单个类别平均精度(AP),把准确率在recall值为Recall = {0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1}时(总共11个rank水平上),求平均值:
AP = 1/11 ∑ recall∈{0,0.1,…,1} Precision(Recall)
这样,在不同的recall水平上,平均的准确率给了模型更好的评估。
另一个平均精度均值(mAP),只是把每个类别的AP都算了一遍,再取平均值:
mAP = AVG(AP for each object class)
因此,AP是针对单个类别的,mAP是针对所有类别的。
在机器视觉目标检测领域,AP和mAP分界线并不明显,只要IoU > 0.5的检测框都可以叫做AP0.5,这时AP和mAP表达都是多类检测的精度,关注点在检测框的精度上。
如果你还不知道IoU是什么,可以移步到我们以前的文章:
参考文献:
- https://medium.com/@jonathan_hui/map-mean-average-precision-for-object-detection-45c121a31173
- https://datascience.stackexchange.com/questions/25119/how-to-calculate-map-for-detection-task-for-the-pascal-voc-challenge
- https://stats.stackexchange.com/questions/61829/relation-between-true-positive-false-positive-false-negative-and-true-negative
本文采用署名 – 非商业性使用 – 禁止演绎 3.0 中国大陆许可协议进行许可。著作权属于“David 9的博客”原创,如需转载,请联系微信: david9ml,或邮箱:yanchao727@gmail.com
或直接扫二维码:

David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024
如果recall到0.6之后就没有了怎么办呢?
recall最后是可以到1.0的 怎么会没有呢 ?
tensorflow 上的tf.metrics.average_precision_at_k是用来计算mAP的吗?
应该是比较类似的,mAP是计算所有rank的平均精度,而tf.metrics.average_precision_at_k是可以指定k的值,k也可以为1,即只计算top-1的。
我的也是recall到0.7就没有值了,请问是什么原因呢?感谢~
不是很理解,也许我没有理解你们的意思 , 召回率怎么会到不了1 ?