特征工程的下一步可能是如何直接操控特征(同域或不同域),而不仅仅是特征选择或特征过滤 — David 9
相信很多初学迁移学习的朋友心里一直有个疑问:迁移学习的模型真的对新应用效果也好吗?更好的迁移模型,在其他应用上表现效果也更好吗?
根据Google Brain在CVPR 2019的研究总结,今天David偷懒一次,只说结论:
答案很大程度上是肯定的!Google Brain的大量实验证明,无论是把神经网络倒数第二层直接拿出来做预测,还是把预训练模型对新应用进行“二次训练”,好的imagenet预训练模型普遍有更好的迁移学习效果:
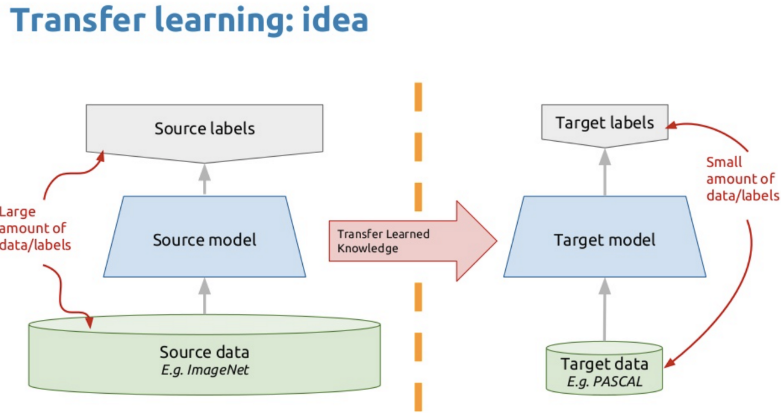
如上,左图是直接把网络倒数第二层特征直接拿出来进行迁移学习(使用Logistic Regression),右图是在新应用上find-tuned的迁移学习表现。可以注意到,只要是模型本来表现就好(横左标),迁移的效果就更好(纵坐标)。从性能最差的MobileNet到性能最好的Inception-ResNet无一例外。
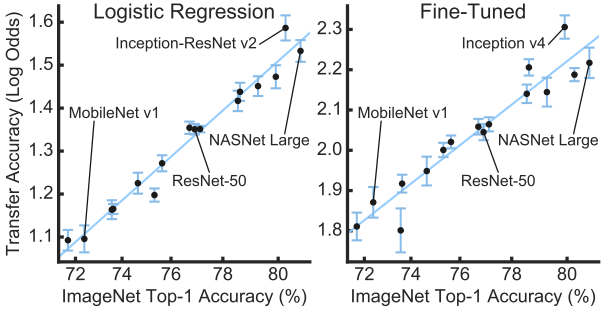
但是,迁移学习并不是就无敌了。文章指出,在迁移学习中一定要慎用正则化,正则方法如 (Dropout, Label Smooth) 用得越少,直接把倒数第二层特征迁移后,效果就越好:
上图从左到右顺着横坐标,是在模型中去掉一些正则化方法的迁移效果,其中“+”号是模型中使用的方法,“-”号是模型中未使用的方法。因为BN(batch norm)不是正则化方法,不会影响迁移学习效果。Dropout就是一种后期的正则化处理,这种操作是对迁移学习有影响的。
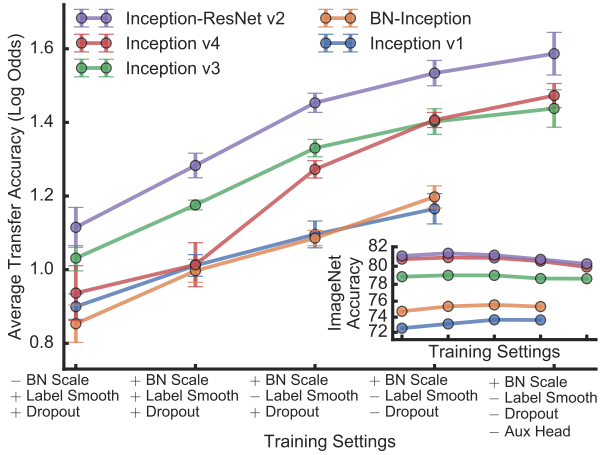
而如果你一定要使用正则化方法,并且要对模型做迁移,建议还是需要(用新数据)fine-tune一下迁移模型,这样对迁移效果影响较小:
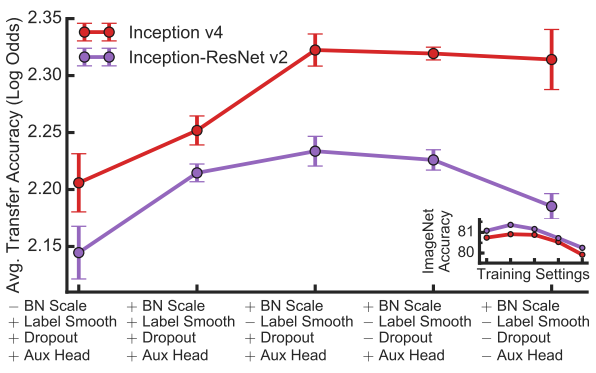
另外,并不是所有迁移学习都能达到显著效果:
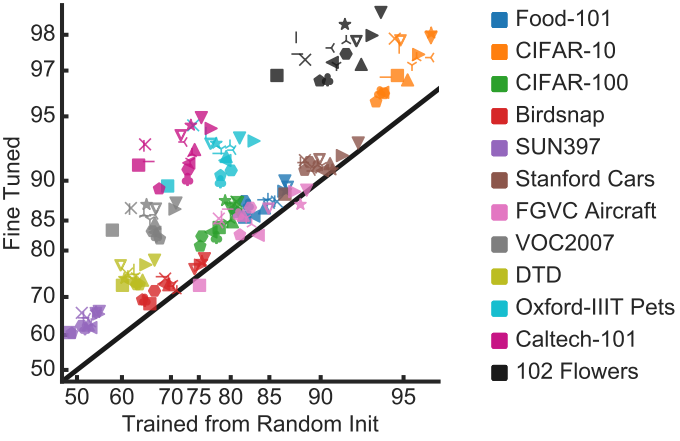
文章指出,对于find-grained分类数据集(大类中含小类,小类中还能分类),如果数据量小的话,迁移学习确实有用,而如果数据量非常大,从头开始训练和迁移学习最后的效果差别不大。如上图,每个点是模型在一个数据集上迁移学习和从头训练的准确率。
参考文献:
- Do Better ImageNet Models Transfer Better?
- http://www.cs.umd.edu/~djacobs/CMSC733/FineGrainedClassification.pdf
本文采用署名 – 非商业性使用 – 禁止演绎 3.0 中国大陆许可协议进行许可。著作权属于“David 9的博客”原创,如需转载,请联系微信: david9ml,或邮箱:yanchao727@gmail.com
或直接扫二维码:

David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024