
与其说AI智能时代,不如说是“泛智能的自动化”时代,或者,以人类为智能核心的 “机器智能辅助”时代 — David 9
最近流传的一些AI“寒冬论”, David 9 觉得很可笑。二十年前深蓝击败卡斯帕罗夫时,自动化智能已经开始发展,只是现今更“智能”而已,而这个更智能、更普及的趋势不是任何人可以控制的。
人类无尽的贪婪和惰性需要外部智能辅助和填补,也许以后的核心不是“深度学习”或者增强学习,但终究会有更“好”的智能去做这些“脏”活“累”活,那些人类不想干或人类做不到的活。。。
CVPR2018上,伊利诺伊大学和Intel实验室的这篇“学会在黑暗中看世界” 就做了人类做不到的活, 自动把低曝光、低亮度图片进行亮度还原:

人肉眼完全开不到的曝光环境下,机器实际是可以还原出肉眼可识别的亮度。
该论文的第一个贡献是See-in-the-Dark (SID)数据集的整理:
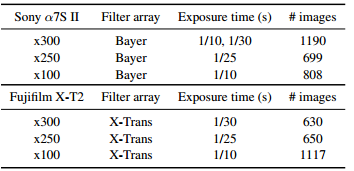
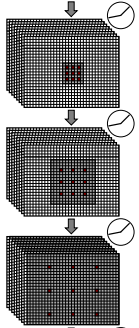
因为目前的数据集没有针对低曝光同时低亮度的图片集,如上图,作者用索尼和富士相机收集低曝光的室内室外图片,同时配对正常曝光的图片用来训练:

训练模型的架构细节包括端到端FCN,扩张卷积,子像素(sub-pixel )还原等。说这些技术之前,我们先看看之前人们是怎么还原低曝光、低亮度图片的:
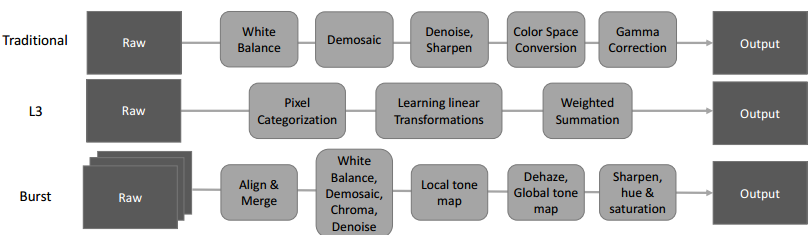
最传统traditional的方法是针对不同照相机,做一些人工调参的操作如白平衡(white balace),去噪,锐化,等等操作。L3方法类似,强调用大量滤波器学习得到传统方法的同等效果。
但这些方法都没有针对快速还原低曝光低亮度的图片。Burst方法虽然可以用来还原高清图片 ,但是计算代价太大。为此,文章采用端到端FCN用来快速还原黑暗中的图片:
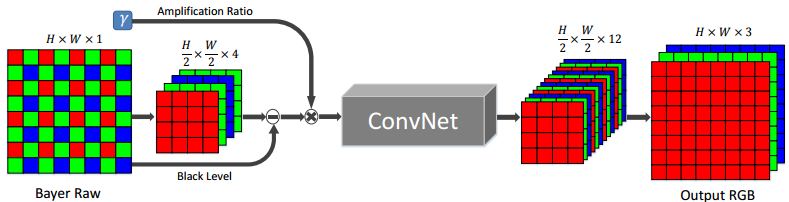
网络头部用的输入不是RGB图像而是Bayer阵列格式的照相机传感信号(实验表面直接用传感器信号效果更好)。紧接着,采用类似stride为2的”带孔”卷积:
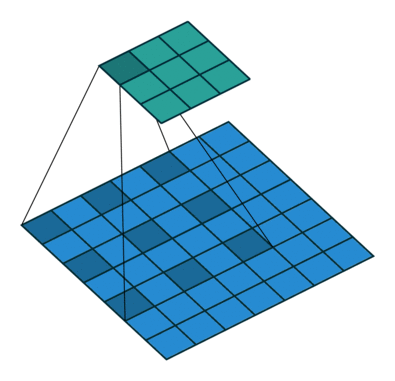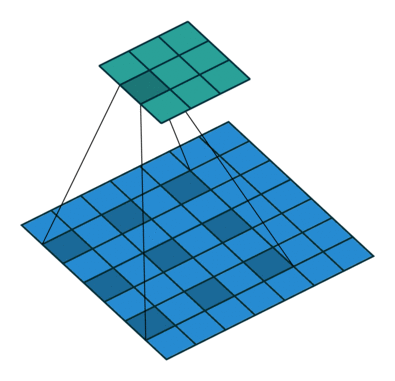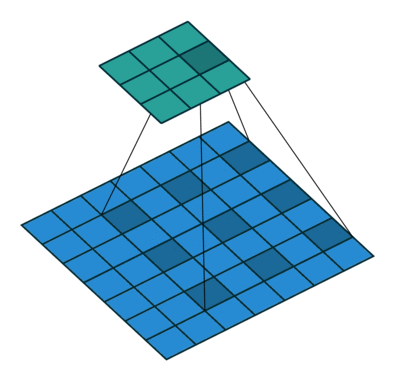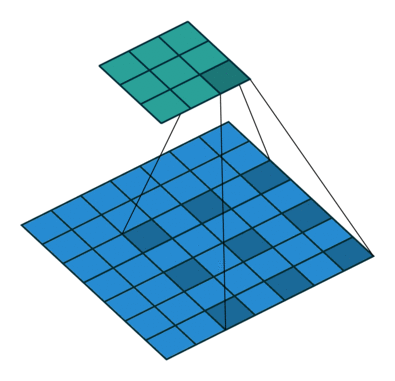
把阵列转换为4个通道,每个通道为1/2 H × 1/2 W , 即长宽为原来的一半。
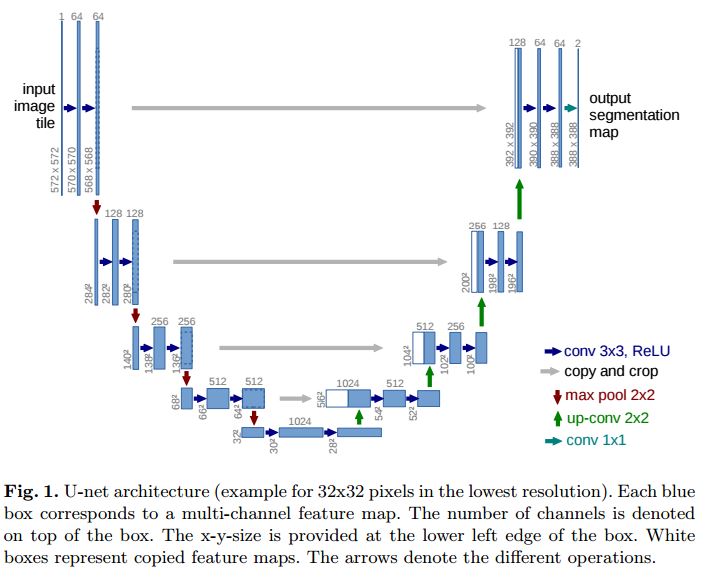
把这4个通道输入到如上图的CovNet中学习(其实是一个基于U-net的FCN全卷积神经网络)。最后输出12个通道的特征图,并用子像素(sub-pixel )还原的方法还原成H×W×3的RGB图片。网络尾部的子像素(sub-pixel )还原示例其实应该是这样的:
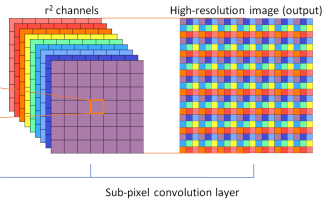
有点像把头部的操作还原的过程。
那么为什么要使用FCN全卷积神经网络?FCN有两个好处:
1. FCN处处都是可学习的卷积核,这适合图片处理这样的全局性较强,灵活度较高的应用。
2. FCN网络中没有全连接层,最后一层的输出可以适应任何输入(不像全连接层只对唯一输入适用),并且输出“所得即所需”。
当然,文章也采用过处理U-net的其他网络变形:
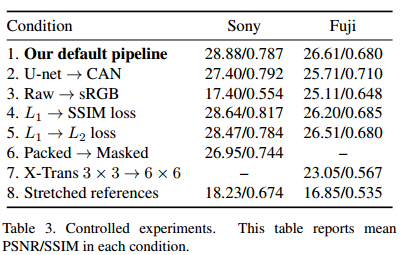
这里的纵列数值代表PSNR/SSIM的指标,前者是图片清晰度的指标,越大越好,后者是与原图相似度的指标,也是越大越好。
上图实验表面,把U-net架构替换成CAN,并不能让图片还原效果更好。U-net和CAN都是FCN的一种,与U-net做跳层连接不同,CAN用的是上下文扩展卷积(后几层的感受野增大,处理速度也变大):
上图也尝试了不同loss,结果并没有显著变化。
参考文献:
- Learning to See in the Dark
- https://www.quora.com/How-is-Fully-Convolutional-Network-FCN-different-from-the-original-Convolutional-Neural-Network-CNN
- https://github.com/cchen156/Learning-to-See-in-the-Dark
- https://nicolovaligi.com/deep-learning-models-semantic-segmentation.html
- Chen_Fast_Image_Processing_ICCV_2017_paper
- https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Shi_Real-Time_Single_Image_CVPR_2016_paper.pdf
本文采用署名 – 非商业性使用 – 禁止演绎 3.0 中国大陆许可协议进行许可。著作权属于“David 9的博客”原创,如需转载,请联系微信: david9ml,或邮箱:yanchao727@gmail.com
或直接扫二维码:

David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024