大脑是天然的特征提取器, 如果不能理解它, 或许可以模拟它, 它蕴含的泛化能力真是惊人 — David 9
许多人相信VR或AR硬件可能是人机交互的未来, 这些欺骗人眼睛和感官的技术, 都是来源于我们对这些感官更深层次的理解. 越是对这些感官了解透彻, 越是容易创造出魔法般的人机交互. 今天David 9想要分析的论文就和感官交互有关, 特别之处是它是人体最复杂的感官 — 大脑 .
很难想象今年CVPR上竟然有这样一篇近乎科幻不可思议的研究, 相信读完你也会兴奋的.
这篇文章本质上的研究, 是从EEG脑电波提取视觉特征, 从而进行我们常见的视觉分类任务(狗? 吉他? 鞋子? 披萨?):

最后一层全连接层做的视觉分类任务是非常常见的.
不同的是前面层不再是从头训练Alexnet, GoogleNet或者VGG, 也不是预训练的神经网络. 而是通过收集脑电波信息, 分析脑电波提取的抽象特征.
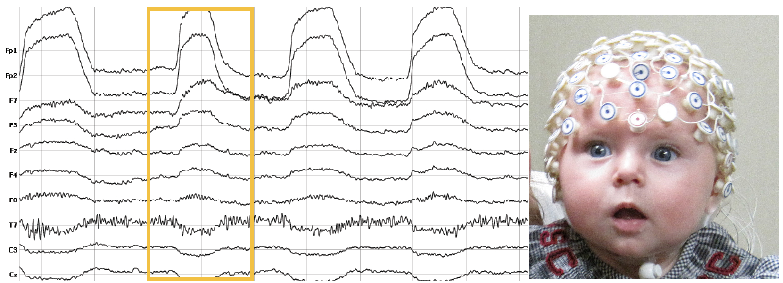
 随着EEG(脑电波记录) 的普及, 实验已经证明人类看到不同种类物体, 就会反应出不同的脑电波反应. 下图是人看到两个Imagenet图片后, 脑电波反应的图谱:
随着EEG(脑电波记录) 的普及, 实验已经证明人类看到不同种类物体, 就会反应出不同的脑电波反应. 下图是人看到两个Imagenet图片后, 脑电波反应的图谱:
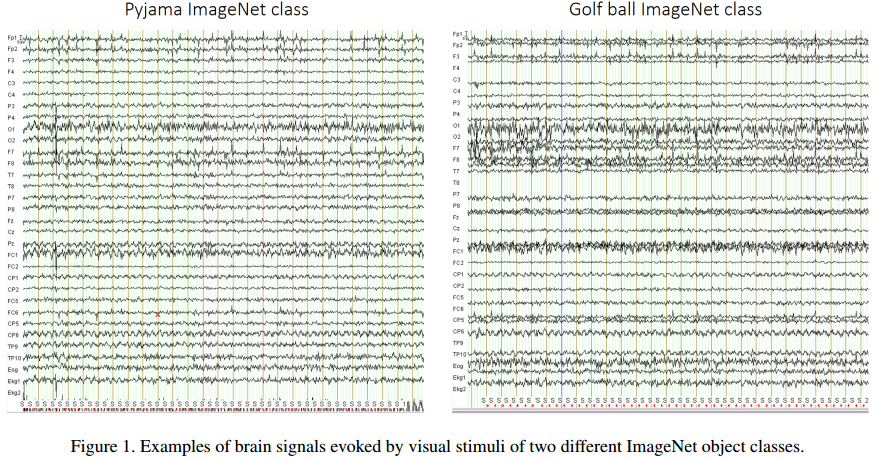
显然在一些频道上, 看不同物体时人脑的脑电波是有差别的, 所以我们可以很自然地假设脑电波反应了人体对物体的识别信息(当然还有许多情感信息, 思考的信息等等).
虽然文章实验用的是imagenet中40个分类, 但是要收集人的脑电波对如此多图片的反应数据, 就是很大的工作量, 不得不佩服.
更令人吃惊的是, 他们找到了抽取这些时序脑电图中特征的方法:
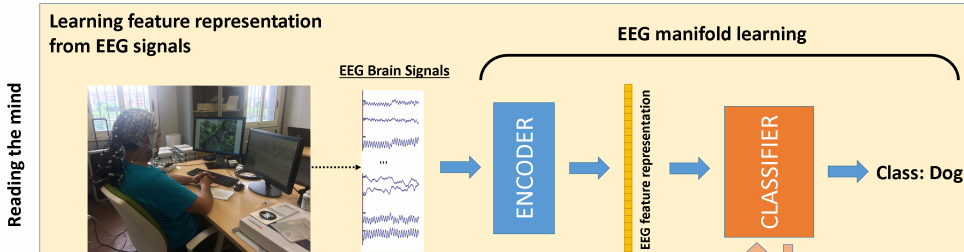
这里的ENCODER就是抽取特征的核心.
为了得到一个好的ENCODER作者尝试了3中架构:
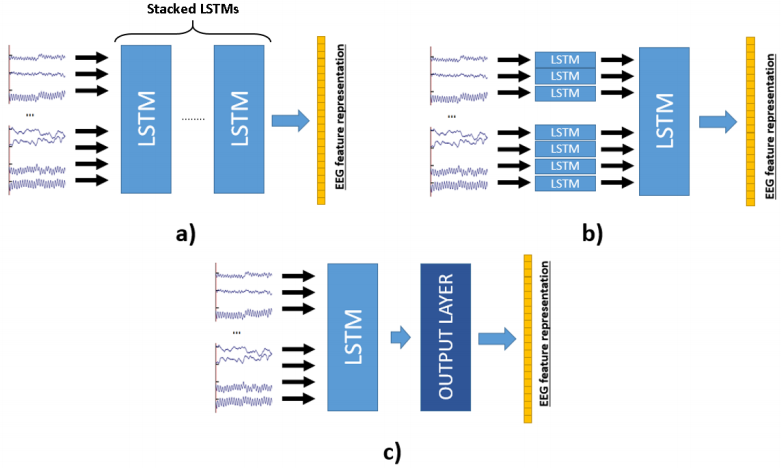
这3种架构文章中分别称为:
a)Common,把所有的脑电波通道同时输入到一个个LSTM中,最后一层的LSTM输出就是需要的特征表征
b)Channel + Common,每个频道分别先输入到单个LSTM,随后汇总后输入到一个大的LSTM中
c)Common+output, 与a)相似,不同的是多了一层output输出层(类似全连层+RELU)
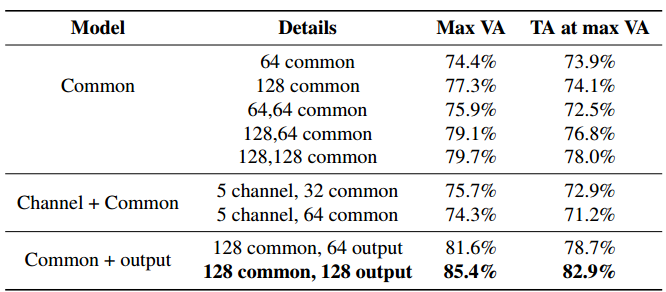
经过实验,文章认为c)架构有最好的泛化能力:
为了证明从脑电波提取的特征的有效性和通用性,文章还把上述学习到的特征表述迁移到一个CNN中,图片的端到端分类(无须进行再次脑电波读取):
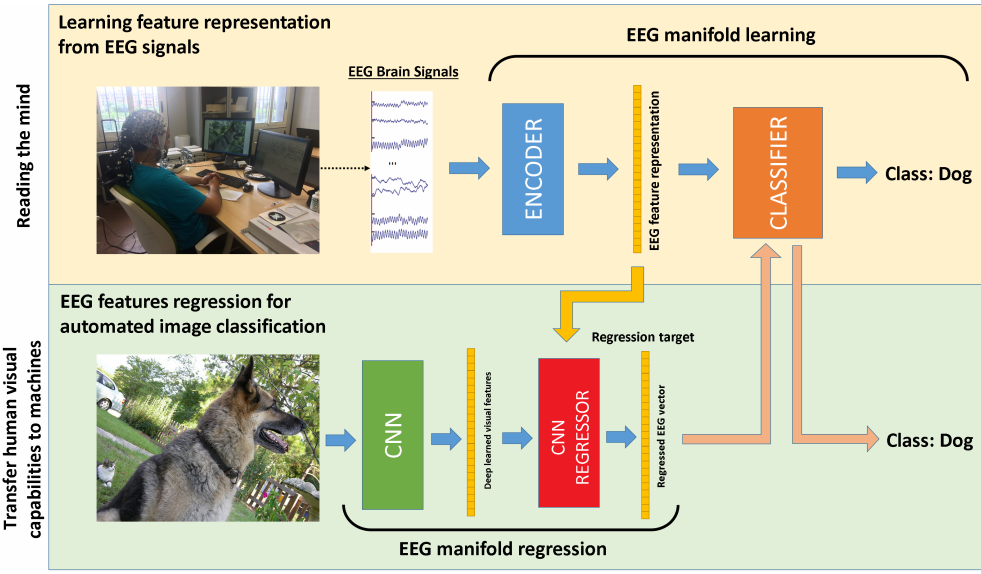
上图的CNN REGRESSOR做到了模拟之前学习到的"图片到特征表征"的映射.
最后一层的CLASSIFIER不变,是抽象特征表征到类别的后续训练(事实上CLASSIFIER可以是SVM, KNN,随机森林,无须太复杂)
虽然实际使用这些提取的特征表征,不比成熟的GoogleNet和VGG准确度高,但是考虑到GoogleNet和VGG的imagenet训练图片集非常丰富,而该论文的脑电波数据集并不像imagenet这样丰富,而且是在脑电波的基础上提取信息的,在Caltech-101子集上能达到70%的准确率已经很不容易了:

参考文献:
- https://arxiv.org/abs/1609.00344
- https://www.quora.com/What-are-the-most-interesting-CVPR-2017-papers-and-why/answer/Zeeshan-Zia-1?srid=pdns
- http://crcv.ucf.edu/papers/cvpr2017/cvpr_eeg_gen_2017_camera_ready.pdf
- https://www.youtube.com/watch?v=9eKtMjW7T7w&t=343s
- https://www.slideshare.net/xavigiro/learning-representations-from-eeg-with-deep-recurrent-convolutional-neural-networks
本文采用署名 – 非商业性使用 – 禁止演绎 3.0 中国大陆许可协议进行许可。著作权属于“David 9的博客”原创,如需转载,请联系微信: david9ml,或邮箱:yanchao727@gmail.com
或直接扫二维码:

David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024