“小数据”激发我们从人类学习本质的角度思考问题. — David 9
如果要得到生成模型或分类模型, 我们可以用GAN或CNN等深度网络. 而对于”小数据“我们往往要换一种思路, 利用RNN的”记忆”能力在图片中反复”琢磨”图像的线条等特征:

通过反复寻求好的”关注点”, 我们用一张样本图片, 就能比较新图片与之差异, 以及和原图片是同一个文字的可能性. 这正是所谓的one shot learning, 即, 从一个样本学习到该样本的整个类. 没错 , “小数据”的泛化能力真是惊人 ! 甚至击败了KNN ,SIAMESE NETWORK等传统相似度比较方式。
论文模拟了人类比较文字的方法,交替比较两个文字的区别,最后给出一个结论:这两个文字是不是同一个文字:
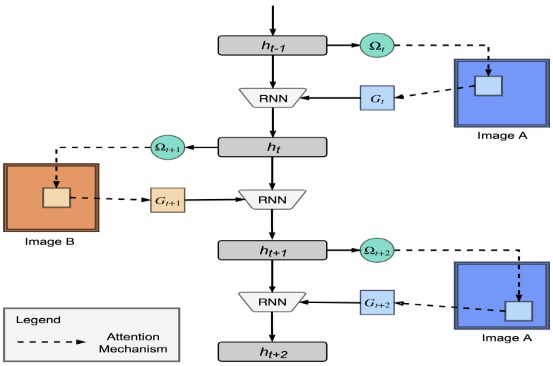
无疑,存储状态和“记忆”的核心是一个RNN网络。
网络的输入是上一次RNN控制器的隐层状态ht-1 和依据上一次关注点获得的关注值Gt (文中形象地叫做”一瞥”:glimpse, 即瞥了一眼的信息)
网络的输出是下一次的隐层状态ht.
值得注意的是, 每次迭代的输入图片是两张对比图片交替输入的(上图的Image A 和Image B). 另外,每次迭代的隐层状态不仅包含了两张图片形似度的信息, 也包含下一次需要的关注点的信息. 即, 由ht 可以推出下一次的关注点参数 Ωt+1.
如果对关注点机制和如何推算出下一个关注点, 我想这篇文章和这篇论文对大家很有帮助.
让我们假设已经明白了关注点是在每次迭代中如何变化并且优化的, 并且我们相信越靠后的迭代, 关注点对于区分两个文字的价值应该越大.
剩下的, 论文主要把关注点评估(这里的Gt ) 加入, 另外结合一些深度学习的技巧.
![]()
![]()
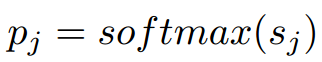
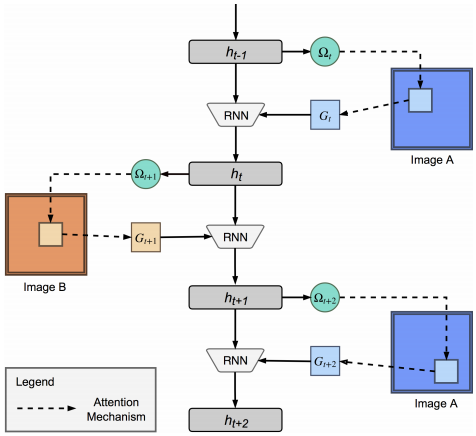
为了加入深度学习属性, 文章没有直接用隐层的输出做相似性比较, 而是像上述加入一个双向LSTM, 把绝对比较值转化为相对比较值, 最后用一些非线性函数和softmax做映射.
使用上述加入深度学习属性的模型,可以达到更好的one shot准确率:
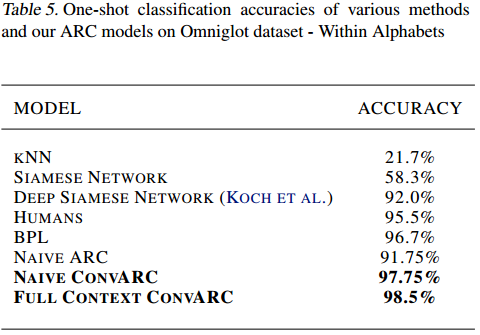
对于实验分析,循环比较器(Attentive Recurrent Comparators)的关注点最后会趋向关注两张图区别较大的部分(注意关注点蓝色窗口移动):

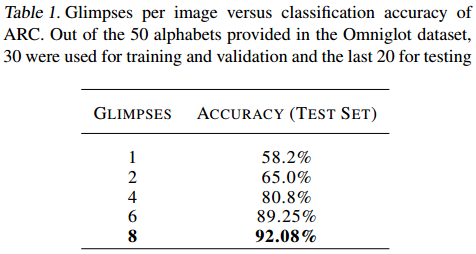
这也导致一开始的几次迭代并不能很好地区分两张图片或文字,而是在后面几次迭代达到了不错的准确率:
参考文献:
- Attentive Recurrent Comparators
- https://www.slideshare.net/JisungDavidKim/oneshot-learning
- https://arxiv.org/pdf/1502.04623.pdf
- https://www.qcloud.com/community/article/971807
- http://kvfrans.com/what-is-draw-deep-recurrent-attentive-writer/
- https://github.com/sanyam5/arc-pytorch
本文采用署名 – 非商业性使用 – 禁止演绎 3.0 中国大陆许可协议进行许可。著作权属于“David 9的博客”原创,如需转载,请联系微信: david9ml,或邮箱:yanchao727@gmail.com
或直接扫二维码:

David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024