把基于概率的自动化叫做AI是否有些可笑? — David 9
原文:An Intuitive Explanation of Connectionist Temporal Classification
聊到CTC(Connectionist Temporal Classification),很多人的第一反应是ctc擅长单行验证码识别:

是的,ctc可以提高单行文本识别鲁棒性(不同长度不同位置 )。今天David 9分享的这篇文章用几个重点直观的见解把ctc讲的简洁易懂,所以在这里就和大家一起补一补ctc 。
首先ctc算不上一个框架,更像是连接在神经网络后的一个归纳字符连接性的操作:
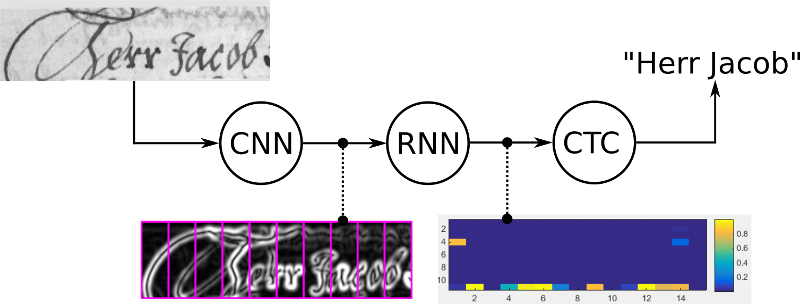
cnn提取图像像素特征,rnn提取图像时序特征,而ctc归纳字符间的连接特性。
那么CTC有什么好处?
因手写字符的随机性,人工可以标注字符出现的像素范围,但是太过麻烦,ctc可以告诉我们哪些像素范围对应的字符:

如上图标注“t”的位置出现t字符,标注o的区域出现o字符。是的就是这样简单,ctc会总结出上述标注规律,不用人工标注,你所要做的只是提供loss函数做模型训练。
CTC是如何工作的?
ctc的编码有一个地方需要注意即是对重复字符的处理,如上述例子中的“to”, 如果真实字符串是“too”,而编码时也为“to”,就会和真实字符串“to”混淆。
所以在重复字符处要引入一个占位符号“-” 。下面是一些例子:

然后,ctc会计算loss ,从而找到最可能的像素区域对应的字符。事实上,这里loss的计算本质是对概率的归纳:
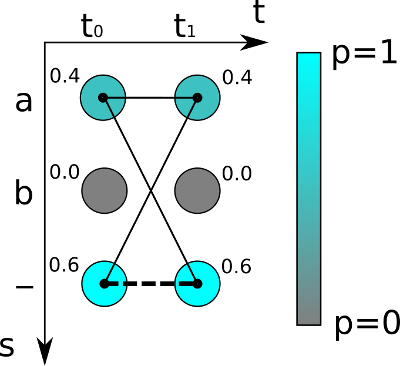
如上图,对于最简单的时序为2的(t0t1)的字符识别,可能的字符为“a”,“b”和“-”,颜色越深代表概率越高。
对于真实字符为空即“”的概率为0.6*0.6=0.36
而真实字符为“a”的概率不只是”aa” 即0.4*0.4 , 实时上,“aa”, “a-“和“-a”都是代表“a”,所以,“a”的概率为:
0.4*0.4 + 0.4 * 0.6 + 0.6*0.4 = 0.16+0.24+0.24 = 0.64
所以“a”的概率比空“”的概率高!通过对概率的计算,就可以对之前的神经网络进行方向传播更新。
最后,ctc的解码也是根据概率获得最高的那条路径:
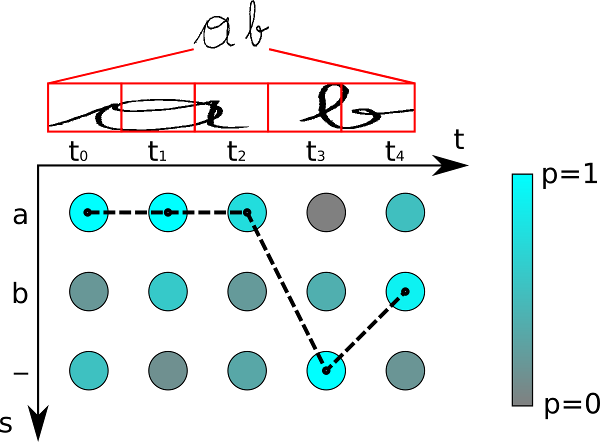
当然,我们讨论到现在,CTC的适用范围还只是单行文本,对于多行如双行的黄牌识别就可能需要介入一些分行算法(line segmentation algorithms 参考【2】)的集成:

对于多行复杂的文本也是一样的:

参考文献:
- https://towardsdatascience.com/intuitively-understanding-connectionist-temporal-classification-3797e43a86c
- Joint Line Segmentation and Transcription for End-to-End Handwritten Paragraph Recognition
本文采用署名 – 非商业性使用 – 禁止演绎 3.0 中国大陆许可协议进行许可。著作权属于“David 9的博客”原创,如需转载,请联系微信: david9ml,或邮箱:yanchao727@gmail.com
或直接扫二维码:

David 9
Latest posts by David 9 (see all)
- 修订特征已经变得切实可行, “特征矫正工程”是否会成为潮流? - 27 3 月, 2024
- 量子计算系列#2 : 量子机器学习与量子深度学习补充资料,QML,QeML,QaML - 29 2 月, 2024
- “现象意识”#2:用白盒的视角研究意识和大脑,会是什么景象?微意识,主体感,超心智,意识中层理论 - 16 2 月, 2024