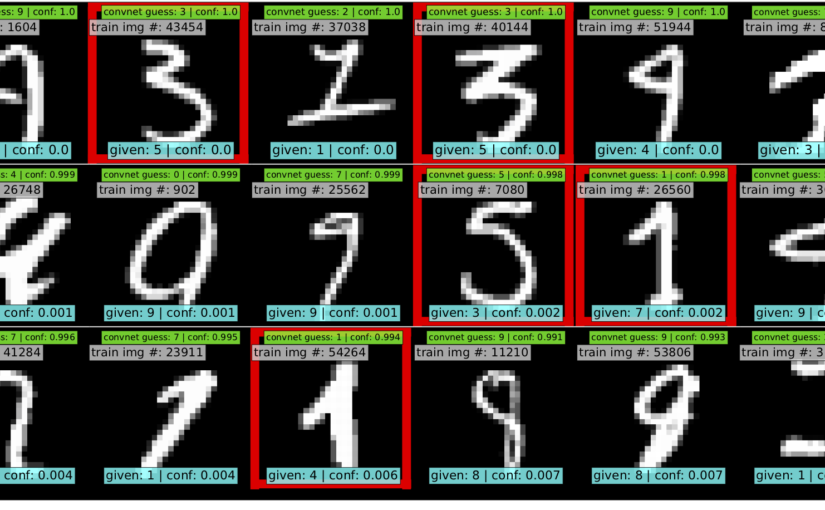
在上一弹我们讲过,如何用同质模型,科学地运用“交叉验证”清洗噪音数据,是CL信心学习的主题。与其他清洗方法相比,CL背后有理论支持,对不平衡的多类问题也可以清洗数据,不需要修改你的原有模型,只要模型对每个样本有概率输出(softmax, 贝叶斯,逻辑回归等。。)
CL背后的原理很朴素,它假设每个样本的标签y~不一定是真的标签,并假设有一个真正的隐含标签y*才是真正的标签。值得强调的是,它的标签“信心”通过高于某个类内概率的平均水平,就认为是较为可信的,即一种per-class的类内信心。
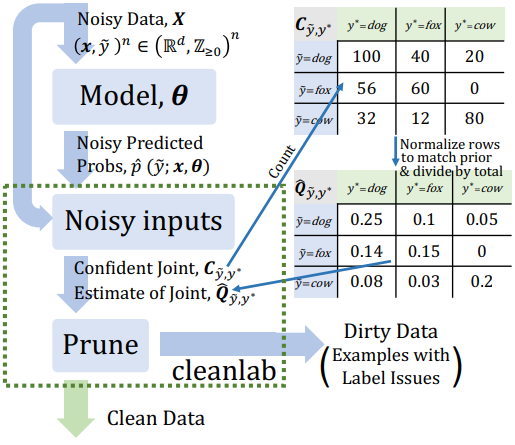
MIT和google也开源了cleanlab库可以实操你的模型支持信心学习。其中接口estimate_confident_joint就是计算了y~和y*的联合概率,即结合类内的信心:
confident_joint, psx = estimate_confident_joint_and_cv_pred_proba(
X=X_train,
s=train_labels_with_errors,
clf=logreg(), # default, you can use any classifier
)
estimate_latent函数就是对y*的估计了,其总共返回了三个估计,其中p(y)即y*的概率估计:
p(y) as est_py, P(s|y) as est_nm, and P(y|s) as est_inv
est_py, est_nm, est_inv = estimate_latent(confident_joint, s=train_labels_with_errors)
其中s是某个样本。
那么问题来了,你如果已经有了自己的一个模型(PyTorch, Tensorflow, MxNet等),怎么快速扩展成可以支持CL信心学习呢?
cleanlab文档中说只要一行就能找出你训练集中的噪音:
from cleanlab.pruning import get_noise_indices
ordered_label_errors = get_noise_indices(
s=numpy_array_of_noisy_labels,
psx=numpy_array_of_predicted_probabilities,
sorted_index_method='normalized_margin', # Orders label errors
)
这并不准确,第一,这只在你的模型相当简单的情况下才可以,第二,这里的psx对象如何计算它还没有清晰给出。
如果要支持自己的复杂模型,这一行是不够的,你需要让你的模型类继承sklearn中的
