世界有时丑陋,我们需要遗忘。
但“遗忘”往往不是我们想的那样。 — David 9
我们很容易注意到,“记忆”或“遗忘”是一件很复杂的事情,对一般人,那些痛苦失落的时光往往印象深刻,但曾经那些快感或幸福会转瞬即逝快速模糊。并且,“主动遗忘”和“彻底遗忘”经常是不存在的事情,更不用说长时记忆与短时记忆究竟是什么?
事实上,记忆是从哪里来的我们都不完全了解,科学家曾经在软体动物身上做实验,把一部分A个体的RNA移植到B, 从而B拥有了A的行为记忆,

试想对于人体,基因对记忆本身的影响更复杂难料。
回归主题,退一步,如果仅仅考虑“彻底遗忘”,并且是在模型层面的遗忘,或许问题会简单一点。
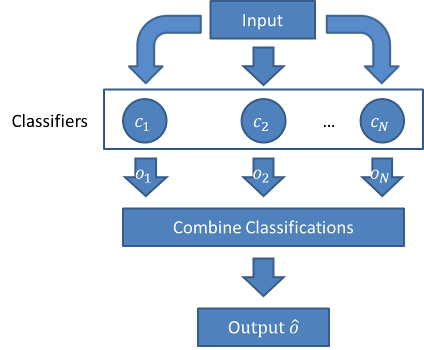
而且把遗忘聚焦在简单的“数据遗忘”,多伦多大学向量学院SISA方法提供了很好的参照。即,把某个训练数据从对神经网络影响中剔除。SISA方法展开是:Sharding(分片),Isolation(隔离), Slicing(切割),Aggregation(聚合),大致架构如下:
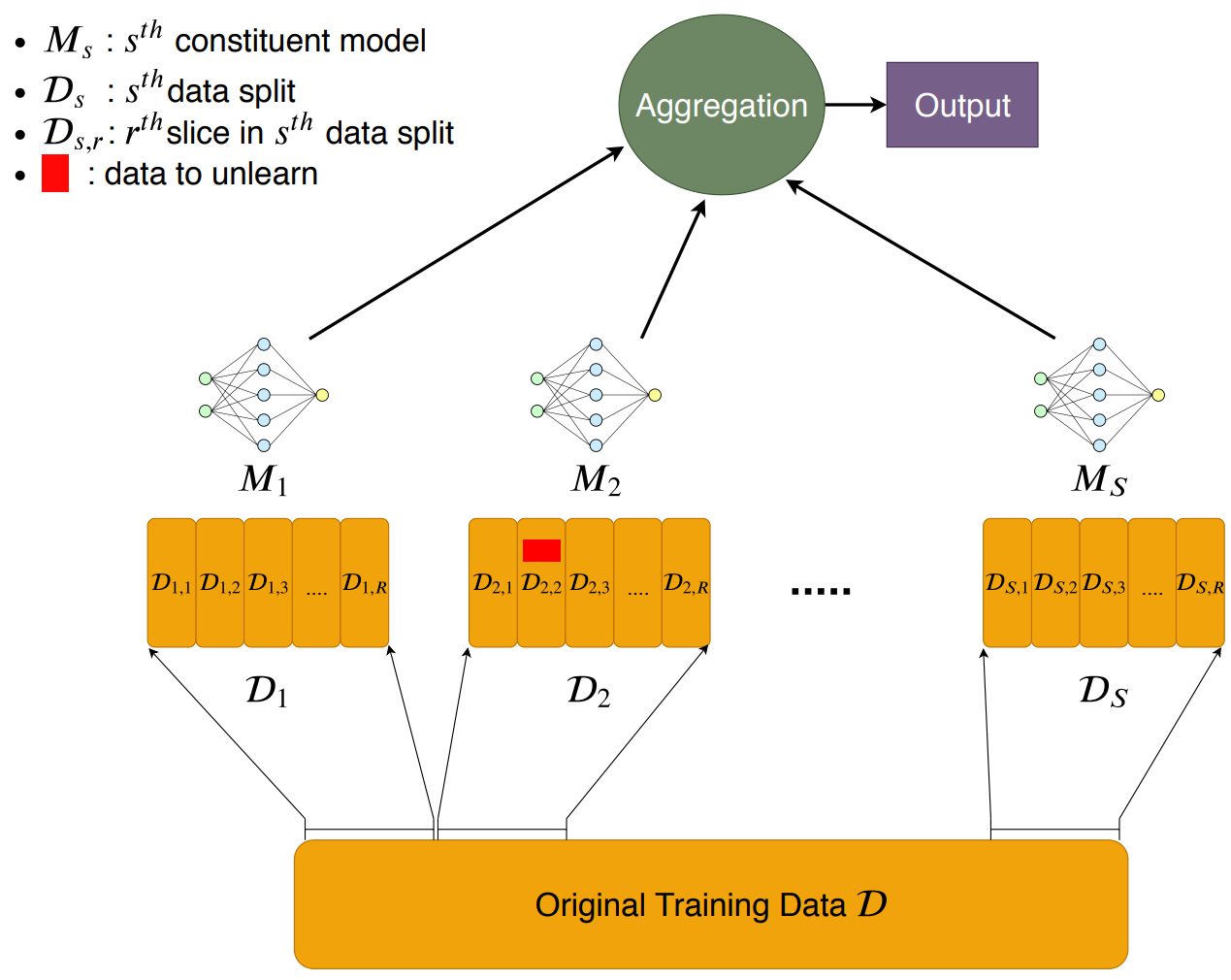
首先,分片,把总的训练数据集D切分成D1,D2,…,Ds等小的数据集,
其次,隔离,把D1,D2,…,Ds分别用M1, M2…Ms等不同神经网络隔离训练, 继续阅读模型”遗忘”的启迪:Machine Unlearning(Forgetting),“主动遗忘”和“彻底遗忘”,长时记忆与短时记忆,多伦多大学向量学院,SISA

 表示集成后模型的泛化误差.
表示集成后模型的泛化误差.