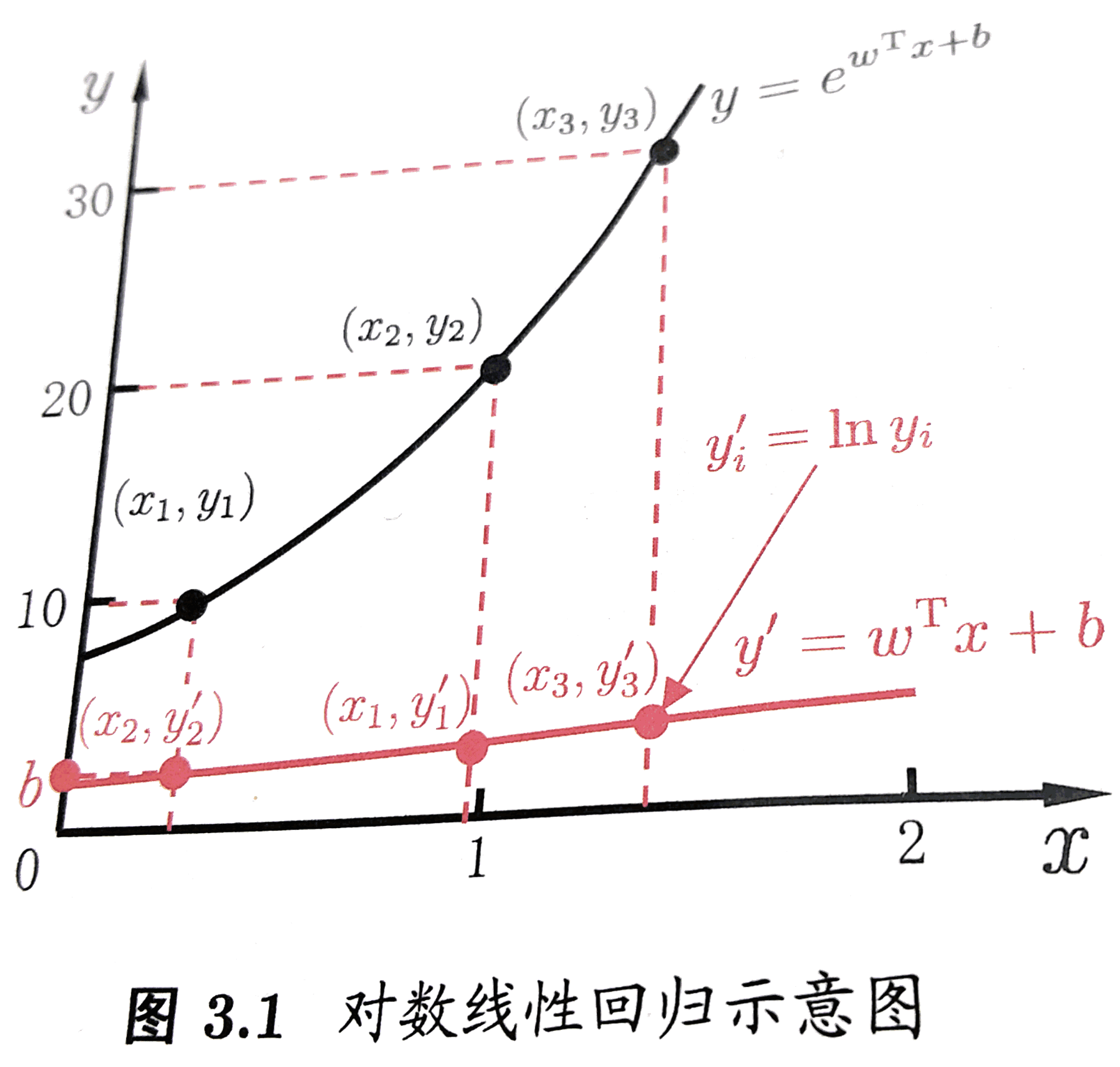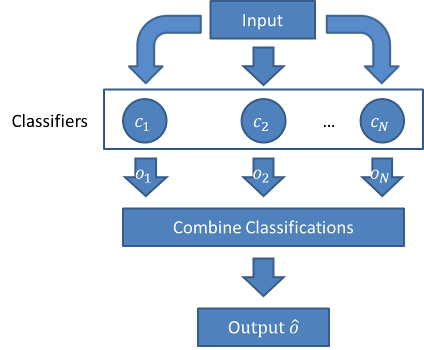
在第3期 “#3 集成学习–机器学习中的群策群力” 中我们谈到, 集成学习是使用一系列学习器进行学习,以某种规则把各个学习结果进行整合,从而获得比基学习器有更好学习效果的集成学习器.
集成学习之所以有更好的学习效果, 与单个基学习器的“多样性”或者说“差异性”密不可分.
正像大自然万物的多样性随处可见, 生物繁衍产生下一代的过程.
集成学习的关键是允许每个单个学习器有各自的差异性, 同时又有一定错误率上界的情况下, 集成所有单个学习器. 正如在繁衍下一代时, 父母各自贡献自己的DNA片段, 取长补短, 去重组得到新的下一代基因组合.
对此, [Krogh and Vedelsby, 1995]给出了一个称之为”误差-分歧分解“(error-ambiguity decomposition)的漂亮式子:

 表示集成后模型的泛化误差. 继续阅读聊聊集成学习和”多样性”, “差异性”的那些事儿~
表示集成后模型的泛化误差. 继续阅读聊聊集成学习和”多样性”, “差异性”的那些事儿~
 , 注意这里
, 注意这里 可以都是高维向量
可以都是高维向量