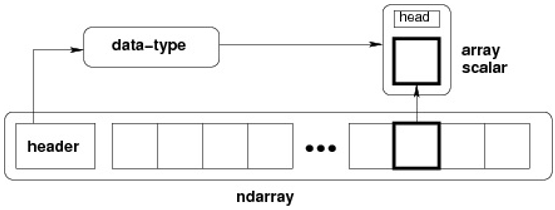
Dask array: 对于多核或者多机器的工作站,为了可以分布式或者多核,又重写Numpy API ,所以有了这个库
最简单的例子大概是这样的:
import numpy as np
x = np.random.random((2,3)) # 在一个cpu上跑
y = x.T.dot(np.log(x) + 1)
z = y - y.mean(axis=0)
print(z[:5])
import cupy as cp
x = cp.random.random((2,3)) # 在GPU上跑
y = x.T.dot(cp.log(x) + 1)
z = y - y.mean()
print(z[:5].get())
import dask.array as da
x = da.random.random((2,3)) # 在许多cpu上跑
y = x.T.dot(da.log(x) + 1)
z = y - y.mean(axis=0)
print(z[:5].compute())
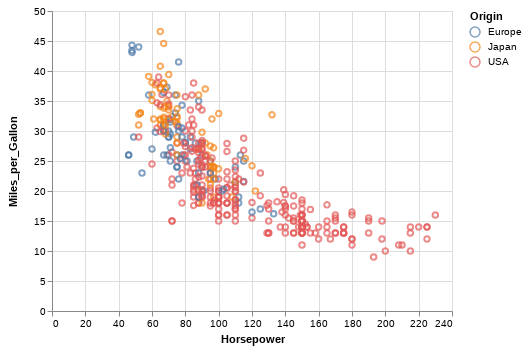
import altair as alt
# to use with Jupyter notebook (not JupyterLab) run the following
# alt.renderers.enable('notebook')
# load a simple dataset as a pandas DataFrame
from vega_datasets import data
cars = data.cars()
# 这里是声明代码,是不是有函数式编程的味道 ?
alt.Chart(cars).mark_point().encode(
x='Horsepower',
y='Miles_per_Gallon',
color='Origin',
)