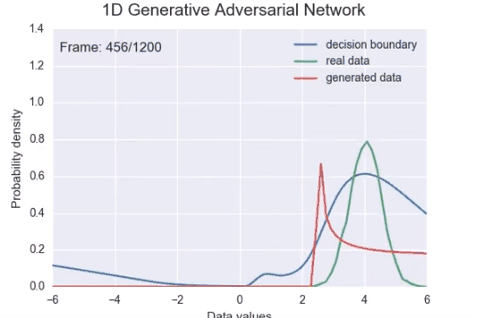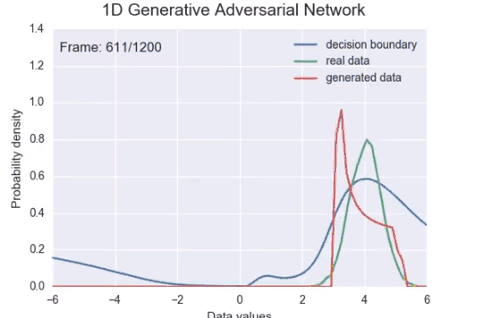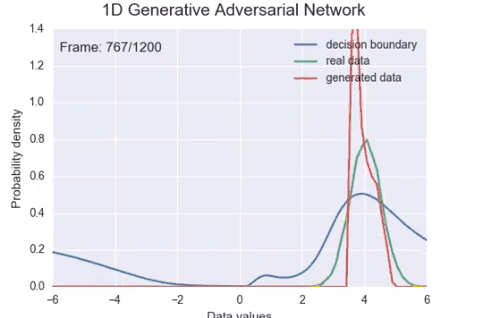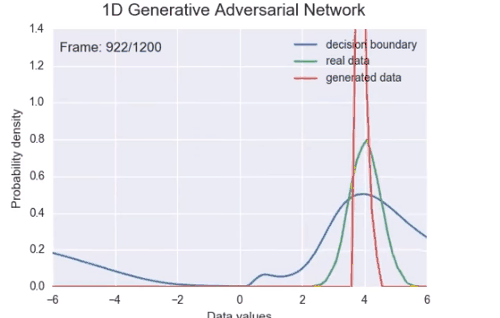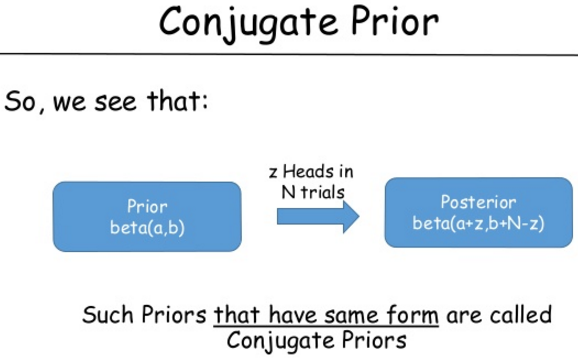
如果不再假设一个分布的参数是固定的,而是去寻找这个参数可能的分布,就可以理解超参数的意义 — David 9
A/B测试一直是David 9想cover的知识点,今天又邂逅一篇相关文章:“tl;dr Bayesian A/B Testing with Python”。于是今天决定讲解一下如何“用python做贝叶斯A/B测试”。所以,现在,两个重要的知识点是 A/B 测试 和 “共轭先验”。
关于A/B测试,其实概念非常简单,简单来说,就是为同一个目标制定两个方案(比如两个页面),让一部分用户使用 A 方案,另一部分用户使用 B 方案,记录下用户的使用情况,看哪个方案更符合设计。A/B测试已经在Web上得到广泛的应用,可以用于增加转化率注册率等网页指标[3].
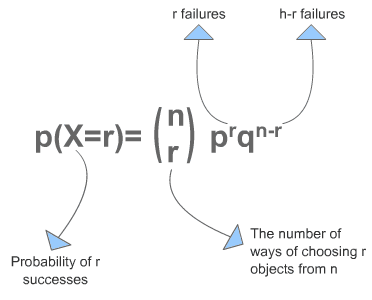
很显然,A方案的转化率可以看作一个二项分布: