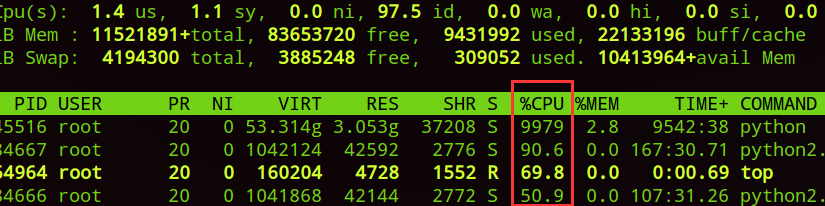
许多朋友使用服务器时,碰巧服务器没有安装GPU或者GPU都被占满了。可是,服务器有很多CPU都是空闲的,其实,把这些CPU都充分利用起来,也可以有不错的训练效果。
但是,如果你是用CPU版的TF,有时TensorFlow并不能把所有CPU核数使用到,这时有个小技巧David 9要告诉大家:
with tf.Session(config=tf.ConfigProto(
device_count={"CPU":12},
inter_op_parallelism_threads=1,
intra_op_parallelism_threads=1,
gpu_options=gpu_options,
)) as sess:
在Session定义时,ConfigProto中可以尝试指定下面三个参数: 继续阅读TensorFlow如何充分使用所有CPU核数,提高TensorFlow的CPU使用率,以及Intel的MKL加速