如果抽象能力足够强, 世间一切关系, 是否都能用距离(Distance)表达? — David 9
接着上一讲, 今天是David 9 的第二篇”NIPS 2016论文精选”: Supervised Word Mover’s Distance (可监督的词移距离). 需要一些nlp自然语言处理基础, 不过相信David 9的直白语言可以把这篇论文讲清晰.
首先, 整篇论文的最大贡献是: 为WMD(词移距离) 提出一种可监督训练的方案, 作者认为原来的WMD距离算法不能把有用的分类信息考虑进去, 这篇论文可以填这个坑 !
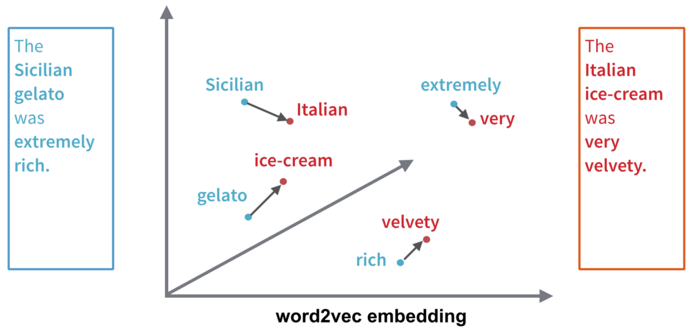
但是, 究竟什么是Word Mover’s Distance(WMD) ? 这还得从word2vec说起:
还记得这张图吧? 在 “究竟什么是Word2vec ?” 这篇文章中我们谈到过word2vec其实是 继续阅读Supervised Word Mover’s Distance (可监督的词移距离) – NIPS 2016论文精选#2