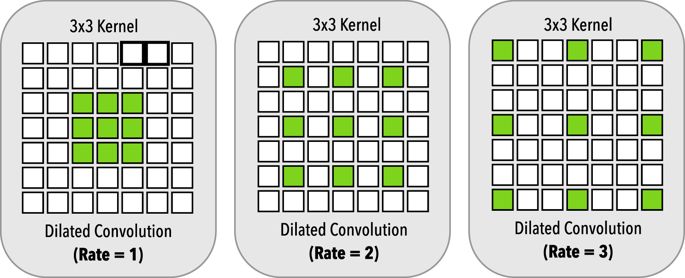
狙击手在放大倍焦前已经经历了大量的小目标训练,这样看似乎是RPN做的好 — David 9
之前在讲SSD时我们聊过SSD的目标检测是如何提高多尺度(较大或较小)物体检测率的。我们来回顾一下,首先,较大的卷积窗口可以卷积后看到较大的物体, 反之只能看到较小的图片. 想象用1*1的最小卷积窗口, 最后卷积的图片粒度和输入图片粒度一模一样. 但是如果用图片长*宽 的卷积窗口, 只能编码出一个大粒度的输出特征.
对于yolov1,每层使用同样大小的卷积窗口, 识别超大物体或者超小物体就变得无能为力(最后一层的输出特征图是固定7*7):
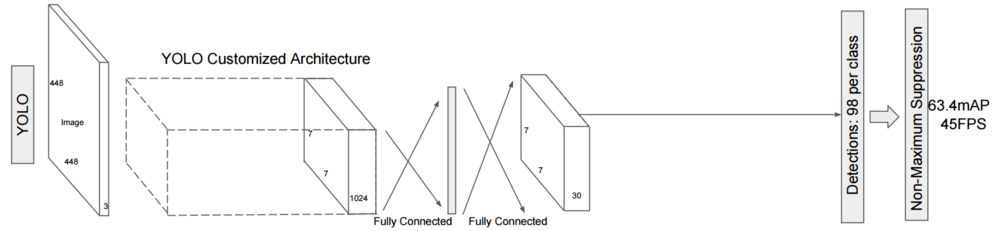
而SSD就更进一步,最后一层的检测是由之前多个尺度(Multi-Scale)的特征图共同生成的:
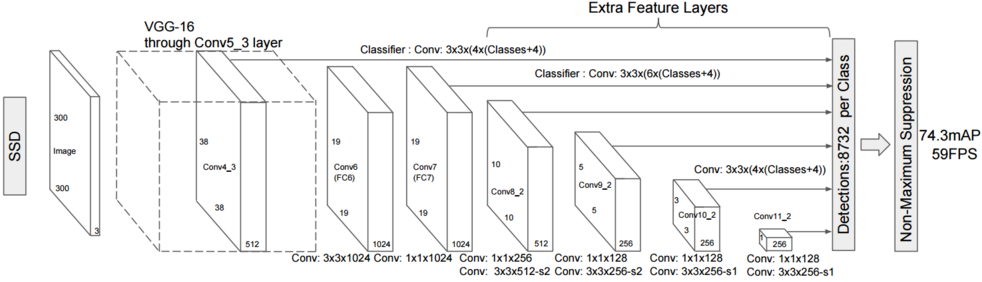
这样SSD在计算复杂度允许的情况下,在多尺度物体的检测上有所提高。但是SSD也有明显缺陷,其最后几层的所谓“多尺度”是有限的(如上图特征图尺寸越小,可以识别的物体越大)。对于极小的目标识别,SSD就显得无能为力了, 继续阅读聊聊目标检测中的多尺度检测(Multi-Scale),从YOLO,ssd到FPN,SNIPER,SSD填坑贴和极大极小目标识别