与其说人类是智能“搜索”机,不如说人类是智能“贪婪”机— David 9
David最近在思考一个问题,表面上看所有智能问题都是“搜索”问题,包括今天我们讨论“好奇心”本质,也可以理解为对“好奇心”算法的搜索。
但是,人类仅仅是一台高级一点的“搜索机”吗?或者说除了“搜索”,“智能”(灵性)是否必须有一些其他重要属性比如“抽象能力”,“信息组织能力” ?换句话,仅仅用显式“搜索”构建的“智能”是不是“伪智能”?
事实上,今天我们探讨的这篇MIT在ICLR 2020的论文,就是这样一种“搜索”出来的“好奇心”。但是,这已经是当今一群聪明人可以设计的较好的“好奇心”机制了。
毫无疑问,好奇心是智能体主动探索外部环境,获取有用经验的驱动力。
在内部,MIT研究人员把“好奇心”设计为一种“代理回报”(proxy rewards)的机制:
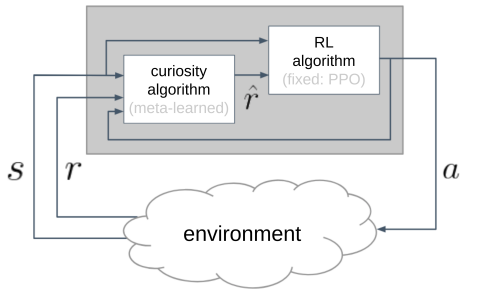
在传统RL算法和外部环境之间又架了一层“好奇心”模块,模块返回的 是RL算法真正训练使用的回报。(并不直接使用环境回报r )。
是RL算法真正训练使用的回报。(并不直接使用环境回报r )。
是RL算法真正训练使用的回报。(并不直接使用环境回报r )。这样对于RL算法,回报不再是“傻乎乎”地锚定某个特定环境,而是可以适应多个环境。事实上该论文的实验就是针对多个RL环境游戏的,如Grid World:
继续阅读ICLR 2020论文精选:“好奇心”的本质探讨,元学习与增强学习(RL)的“好奇心”机制,好奇心算法搜索,智能体的适应力增强