端到端学习是那么吸引人, 因为它与理想的”自治”学习是那么近. — David 9
我们离完全”自治”的AI系统还很远很远, 没有自我采集样本的能力, 没有自己构建模型的能力, 也缺少”端到端” 学什么就像什么的灵活性. 而最近Facebook 人工智能研究所(FAIR)的研究人员公开了一个具有谈判新能力的对话智能体(dialog agents),并开源了其代码, 在”端到端” 这一方向上更进了一步:
-
论文地址:Deal or No Deal? End-to-End Learning for Negotiation Dialogues
-
开源地址:https://github.com/facebookresearch/end-to-end-negotiator
这篇文章的突破仅限于智能对话, 更像是一篇专利, 教大家如何用一堆神经网络训练一个智能对话来获得谈判最终利益. 另外值得注意的是该pytorch项目虽然开源, 但是是经过 creativecommons的NonCommercial 4.0 非商业化协议保护的, 即, 你可以研究和使用代码, 但是你不能直接用它做商业用途.
言归正传, David 9 想说的是, 这个近乎科幻的对话机器人, 其实并没有那么神奇.
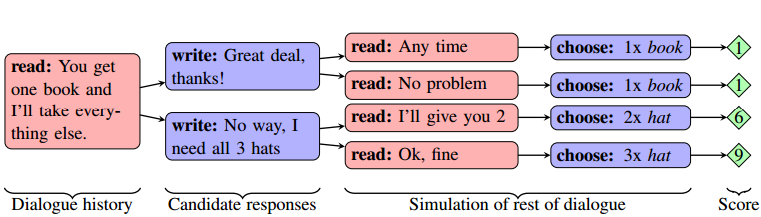
首先看看Facebook一伙人怎么收集对话(dialog)数据的 :
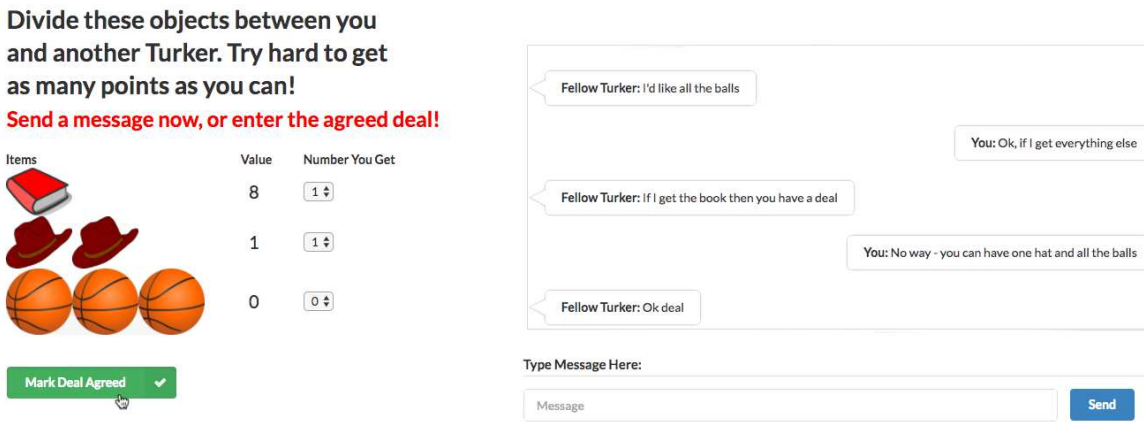
Facebook这伙人收集的数据是从亚马逊 Mechanical Turk 交易网站上 买来的, $0.15一个对话, 总共买了5808个对话. 继续阅读业界 | 扒一扒Facebook人工智能谈判模型 — Facebook开源的”端到端”强化学习模型