这一弹,接着上一期,这次,我们要解释一种典型的机器学习算法——动态主题模型(Dynamic Topic Model)。
概率主题模型和概率图模型是每个做文本挖掘的学者的必学课题。其中最常见的主题模型是隐含狄利克雷分布(LDA)。当然,本文的动态主题模型也是主题模型的一种,不过为了方便理解,我们还是来回顾一下LDA。
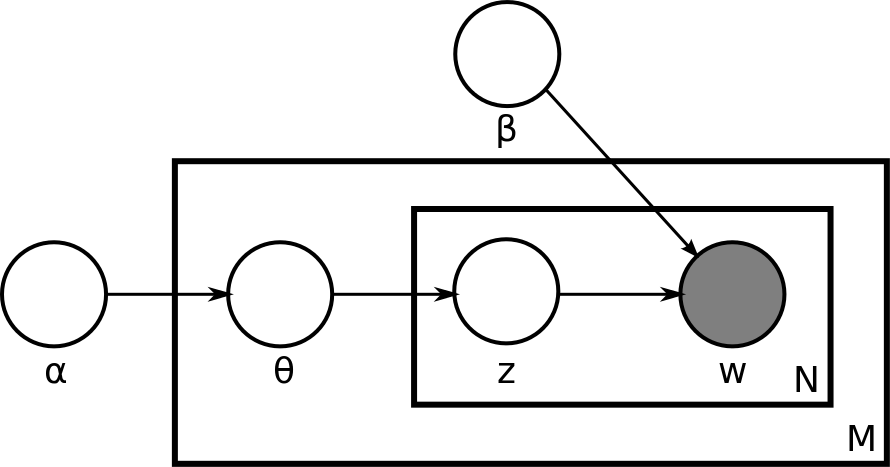
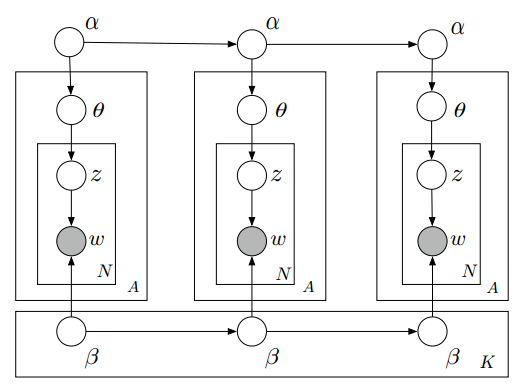
我们定义:
α 是狄利克雷先验的参数,是每个文档可能的主题分布。

β 是狄利克雷先验的参数,但是,它是每个主题可能的文字分布。

这一弹,接着上一期,这次,我们要解释一种典型的机器学习算法——动态主题模型(Dynamic Topic Model)。
概率主题模型和概率图模型是每个做文本挖掘的学者的必学课题。其中最常见的主题模型是隐含狄利克雷分布(LDA)。当然,本文的动态主题模型也是主题模型的一种,不过为了方便理解,我们还是来回顾一下LDA。
我们定义:
α 是狄利克雷先验的参数,是每个文档可能的主题分布。
β 是狄利克雷先验的参数,但是,它是每个主题可能的文字分布。
上一期的Pycon 2016 tensorflow 研讨会总结 — tensorflow 手把手入门 #第二讲 中, 谈到过word2vec, 但是究竟什么是Word2vec ? 以及skip-Gram模型和CBOW模型究竟是什么? 也许还有小伙伴不是很明白, 这一次我们来好好讲一下这两种word2vec:
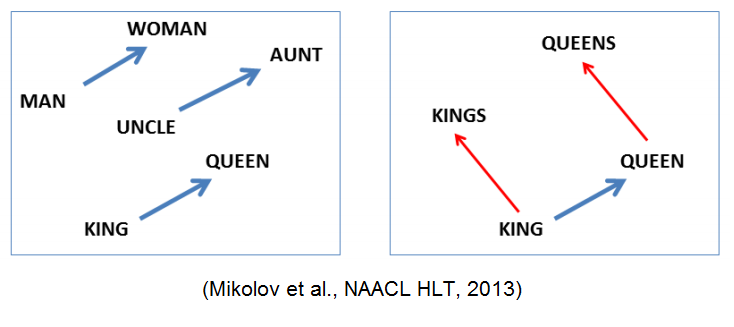
其实, 用一个向量唯一标识一个word已经提出有一段时间了. Tomáš Mikolov 的word2vec算法的一个不同之处在于, 他把一个word映射到高维(50到300维), 并且在这个维度上有了很多有意思的语言学特性, 比如单词”Rome”的表达vec(‘Rome’), 可以是vec(‘Paris’) – vec(‘France’) + vec(‘Italy’)的计算结果.
接下来, 上word2vec示意图:
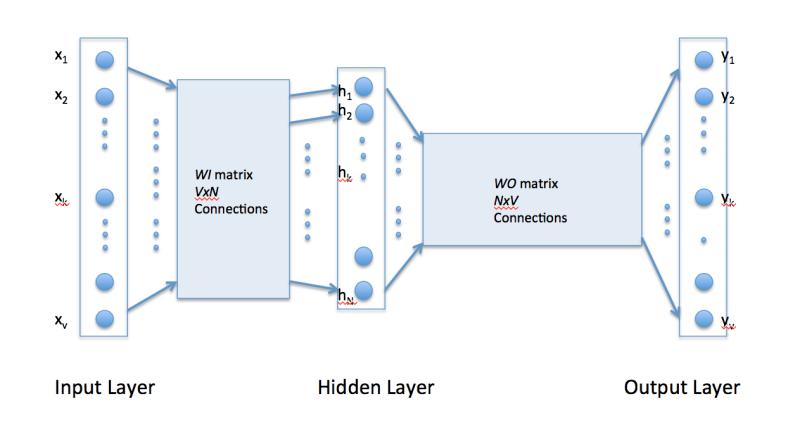
很显然, word2vec是只有一个隐层的全连接神经网络, 用来预测给定单词的关联度大的单词. 继续阅读究竟什么是Word2vec ? Skip-Gram模型和Continuous Bag of Words(CBOW)模型 ?
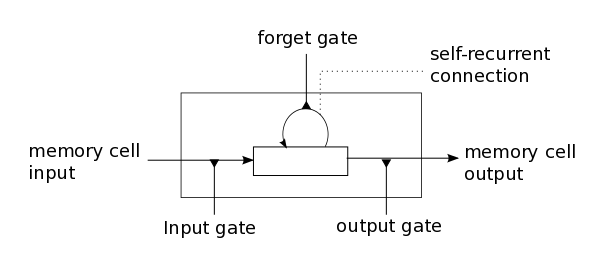
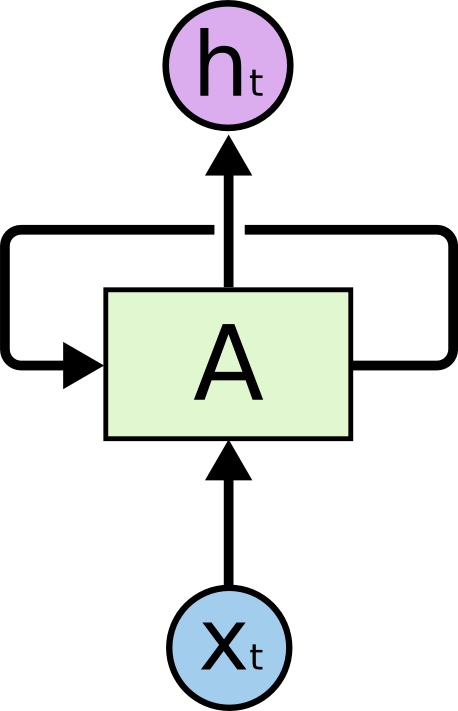
人们的每次思考并不都是从零开始的。比如你在阅读这篇文章时,你基于对前面的文字的理解来理解你目前阅读到的文字,而不是每读到一个文字时,都抛弃掉前面的思考,从头开始。你的记忆是有持久性的。
传统的神经网络并不能如此,这似乎是一个主要的缺点。例如,假设你在看一场电影,你想对电影里的每一个场景进行分类。传统的神经网络不能够基于前面的已分类场景来推断接下来的场景分类。
循环神经网络(Recurrent Neural Networks)解决了这个问题。这种神经网络带有环,可以将信息持久化。