机器视觉是一场科学家与像素之间的游戏 — David 9
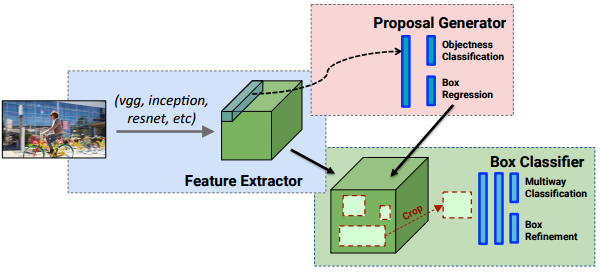
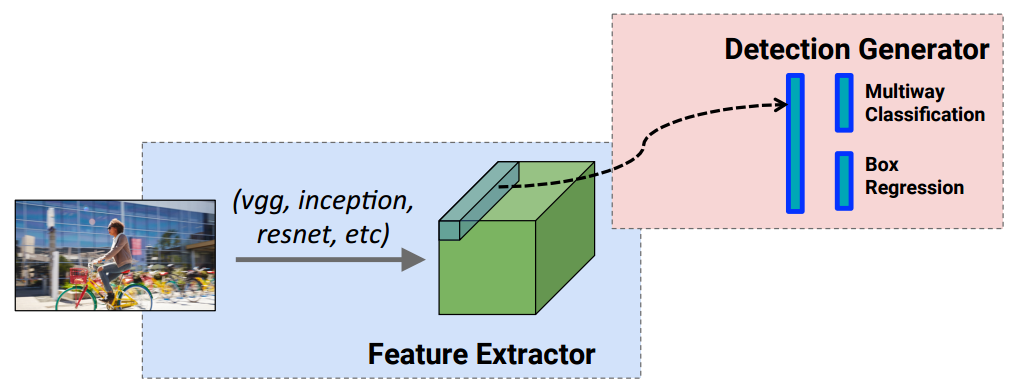
上一期,理解了YOLO这样的实时检测是如何”看一眼“进行检测的, 即让各个卷积特征图(通道)蕴含检测位置和分类置信度的信息(即下图的Multiway Classification和Box Regression):
 对于卷积的本质, David 9需要总结下面两点:
对于卷积的本质, David 9需要总结下面两点:
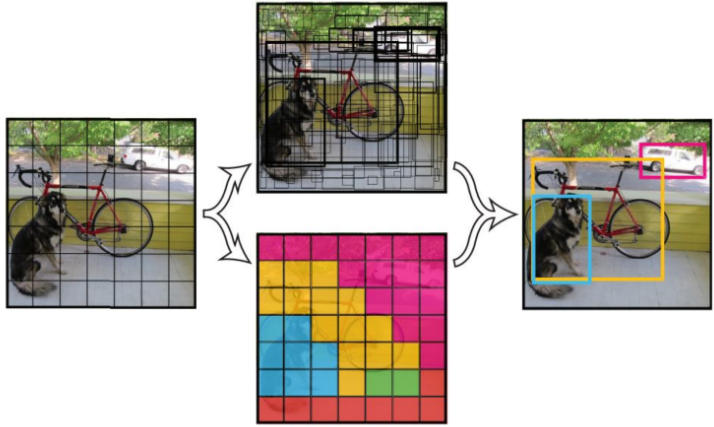
1. 单纯的卷积不会造成信息损失. 只是经过了层层卷积, 计算机看到了“更深”的图片, 输入图片被编码到最后一层的输出特征图(通道)
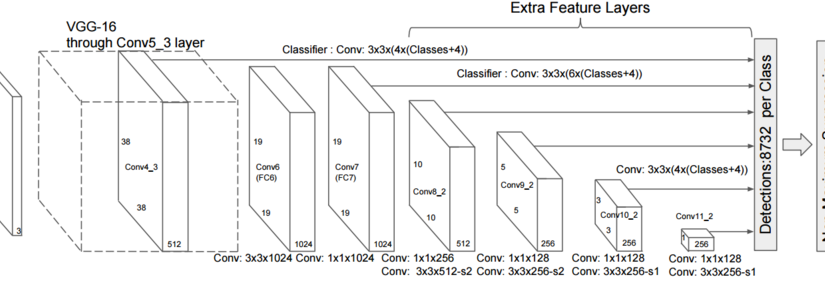
2. 较大的卷积窗口可以卷积得到的输出特征图能够看到较大的物体, 反之只能看到较小的图片. 想象用1*1的最小卷积窗口, 最后卷积的图片粒度和输入图片粒度一模一样. 但是如果用图片长*宽 的卷积窗口, 只能编码出一个大粒度的输出特征. 即, 输出特征图越小, 把原始图片压缩成的粒度就越大. 继续阅读机器视觉 目标检测补习贴之SSD实时检测, Multibox Single Shot Detector