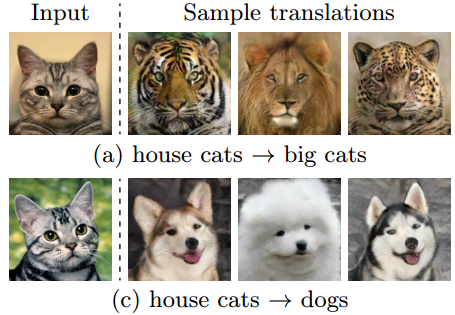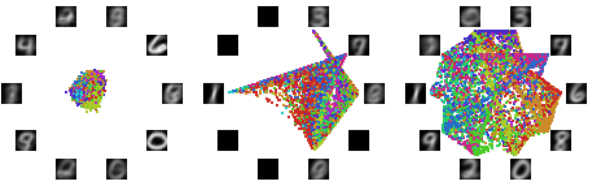
人类是如此擅长“无监督”,以至于我们经常用肤浅的认知作出荒谬的结论 — David 9
人类擅长“无监督”,往往是因为“滥用”过往的经验妄下结论; 而AI模型的“无监督”,是对数据“妄下”的结论。自从有了深度网络的“大锤”,曾经传统聚类的钉子(k-means, 谱聚类等)似乎都被敲了一遍。
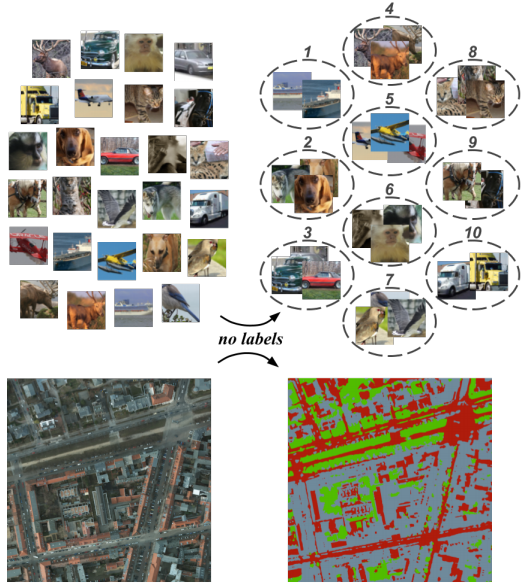
而强行结合传统聚类的深度学习方法,缺乏语义过滤,谁能保证选取的特征都是对聚类任务有意义的?(回过头还得做PCA和白化)
别忘了,人类妄下的结论,都是有语义因果(我们有内在逻辑)。而机器对数据妄下的结论,缺乏因果联系。
为了摒弃传统聚类和神经网络的强拼硬凑,IIC(不变信息聚类)被提出 。IIC没有用传统聚类,而是对CNN稍作改动,用互信息最大化目标函数和双输入(two head)CNN的架构:
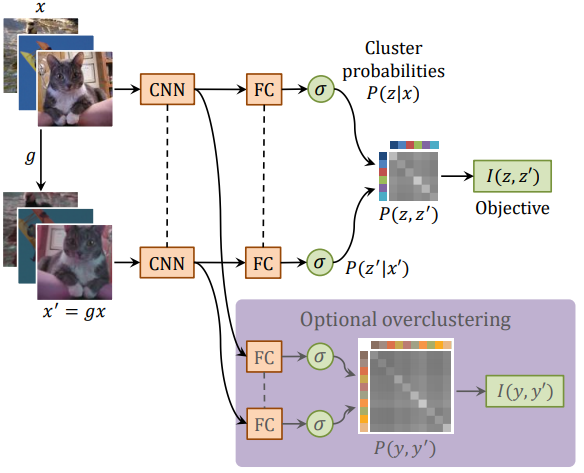
重要的地方有3点,
一, CNN网络用了双输入(不要误以为用了两个CNN,注意虚线部分是共享权重的)。为了做到无监督,模型每拿到一张图片x,都对这张图片做一次转换操作(平移、旋转或crop)得到另一张图片x’ 。因此,训练时是两次正向传播 + 一次反向传播的模式,把x,x’两张图片的两个输出z,z’一次性得到再做loss计算。
继续阅读“不变信息聚类”:满足你对无监督深度聚类的一点幻想,Invarient Information Clustering 深度网络 @牛津大学