不存在纯粹的无监督,那些较“高明”的无监督往往需要对先验做“高明”的处理 — David 9
接着之前的自监督系列,先回顾一下david对自监督的广义概括:
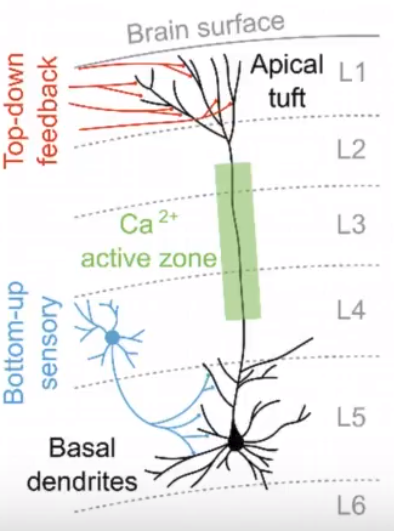
自监督是在已有信息基础上,挖掘额外信息,并进一步强化和丰富已有信息的过程 — David 9
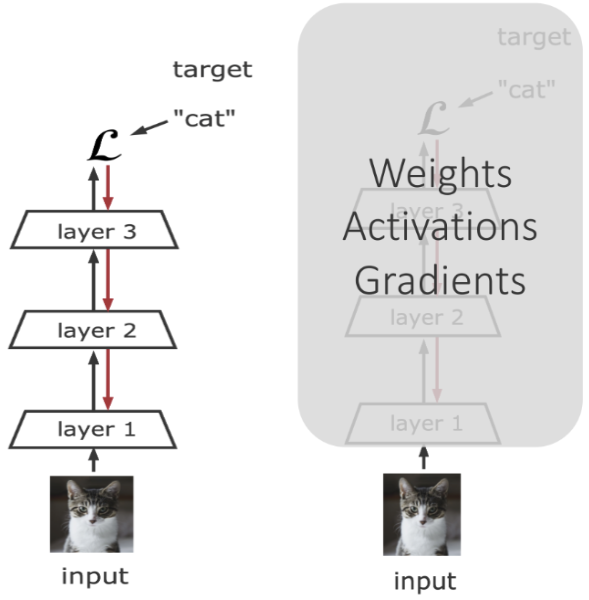
总的来说,“自监督”是有监督学习,并且是半监督的,之所以不直接叫做半监督,是因为它不是简单无监督和有监督拼凑(当然也有营销成分 ),它用各种“更高明的”(包含人类先验的)方式利用大量无标签的样本,自我强化和丰富已有的有标签样本模型。
),它用各种“更高明的”(包含人类先验的)方式利用大量无标签的样本,自我强化和丰富已有的有标签样本模型。
这里的“更高明的”方法总结有两种:
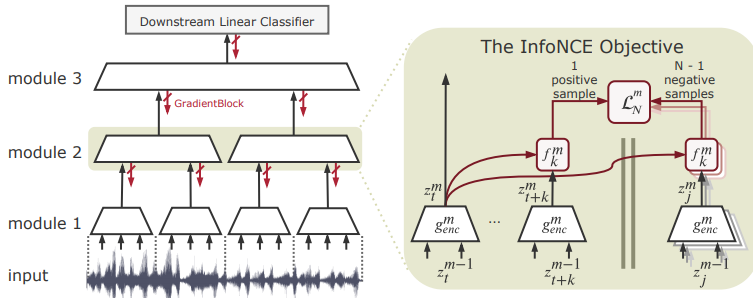
1. 利用更复杂的(加入人类先验的)loss。david之前谈到的InfoMax模型就是典型例子。
2. 利用大量“数据增强”方法训练模型。注意这也是加入人类先验的(数据增强方法不能随意选择)。
我们今天要谈的是第二种方法。即:“数据增强式”自监督。
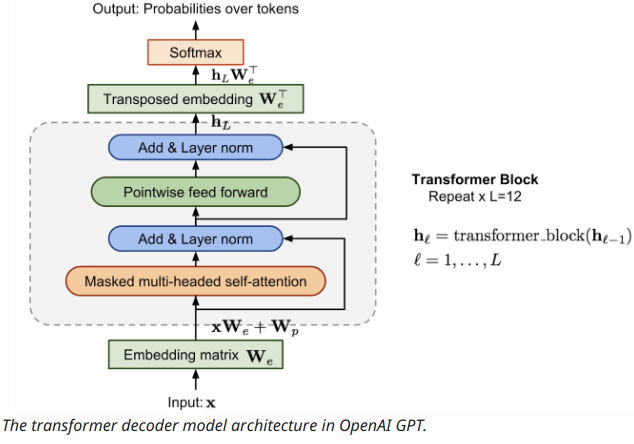
下面是前阵子Google两篇曝光度较高的两篇文章,都用到了这种“数据增强式”自监督: