2018也许是AutoML(自动化机器学习)的探索元年。就让我们从AutoML聊起。
1. AdaNet — 一个基于TensorFlow的开源神经网络自动学习项目。
也许你之前听过Auto-Keras 和 Auto-Sklearn ,但是如果要认真去做神经网络的AutoML,AdaNet 有许多值得借鉴的地方。
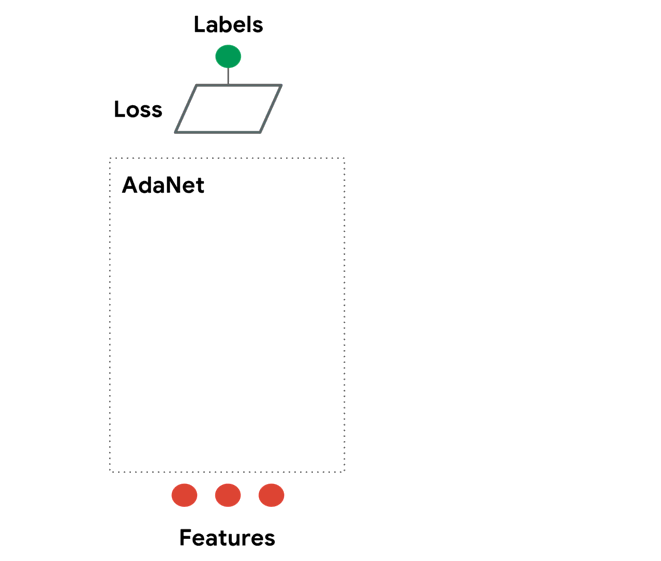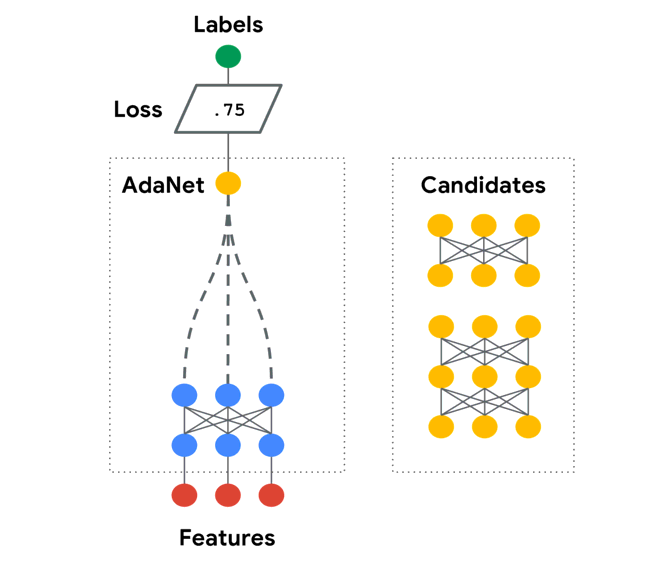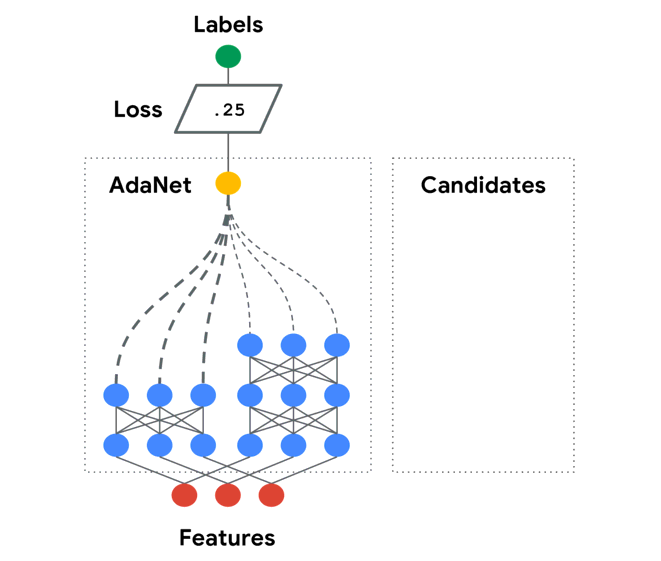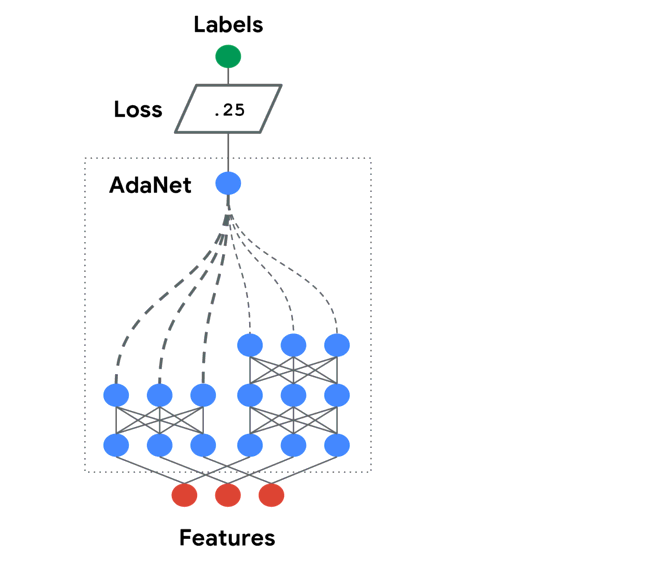
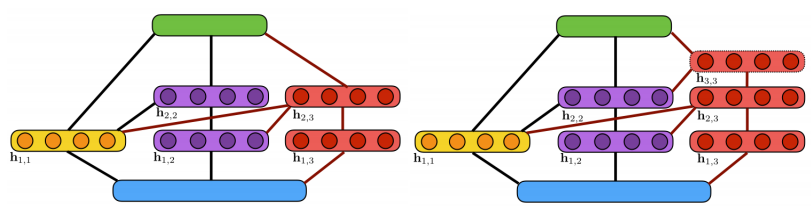
如上图,AdaNet会在网络层中尝试使用不用的候选(Candidates)结构和参数。并且自己维护一个Adanet loss(带正则):
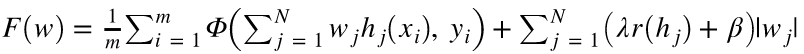
2018也许是AutoML(自动化机器学习)的探索元年。就让我们从AutoML聊起。
1. AdaNet — 一个基于TensorFlow的开源神经网络自动学习项目。
也许你之前听过Auto-Keras 和 Auto-Sklearn ,但是如果要认真去做神经网络的AutoML,AdaNet 有许多值得借鉴的地方。
如上图,AdaNet会在网络层中尝试使用不用的候选(Candidates)结构和参数。并且自己维护一个Adanet loss(带正则):
如果你想成为大师,是先理解大师做法的底层思路,再自己根据这些底层思路采取行动? 还是先模仿大师行为,再慢慢推敲大师的底层思路?或许本质上,两种方法是一样的。 — David 9
聊到强人工智能,许多人无疑会提到RL (增强学习) 。事实上,RL和MDP(马尔科夫决策过程) 都可以归为策略学习算法的范畴,而策略学习的大家庭远远不只有RL和MDP:
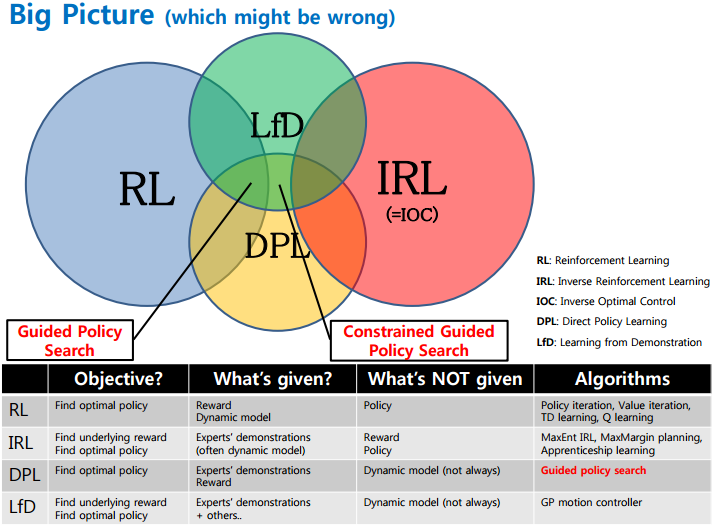
我们熟知的RL是给出行为reward(回报)的,最常见的两种RL如下:
1. 可以先假设一个价值函数(value function)然后不断通过reward来学习更新使得这个价值函数收敛。价值迭代value iteration算法和策略policy iteration算法就是其中两个算法(参考:what-is-the-difference-between-value-iteration-and-policy-iteration)。之前David 9也提到过价值迭代:NIPS 2016论文精选#1—Value Iteration Networks 价值迭代网络) 继续阅读GAN+增强学习, 从IRL和模仿学习, 聊到TRPO算法和GAIL框架, David 9来自读者的探讨,策略学习算法填坑与挖坑
如果你要选验证集或测试集,就选那些你预料未来数据的样子(Choose dev and test sets to reflect data you expect to get in the future and want to do well on)— 吴恩达
前不久吴恩达新书“机器学习念想”(Machine Learning Yearning)手稿完工(不知道这样翻译会不会被打。。)David 9 忍不住拜读 ,把读后感总结如下,欢迎指正和交流:
纵观全书分三部分:
事实上,上手深度学习(机器学习)项目最先要做的和模型本身关系不大,而是构思性能验证系统和错误分析的有效机制。
艺术品最华丽的可能是最后的润色,但其构思、规划以及推敲往往占据大师平时更多心力:

同样,构建一个高效的深度学习系统,首先要有一个好的验证体系、推敲整理过的数据集、高效的错误分析机制,这样最后的润色(模型优化)才能水到渠成。
1. 谈谈验证(测试)集怎么选?
书中建议是,如果你要选验证集或测试集,就选那些你预料未来数据的样子。因此训练集样本分布不需要和验证集(测试集)相同。用白话说就是以你预料“现场”的样本分布为准。 继续阅读吴恩达新书《Machine Learning Yearning》读后感,验证(测试)集怎么选?如何高效分析性能?降低可避免偏差和方差?实操经验总结

