如果你要帮助别人学习,你应该让他多犯错,还是让他少出错?— David 9
试想这样一个未来,所有的AI模型构建的范式都分为两部分:1. 从自然界自动收集所有有利于构建模型的信息数据,2. 自动构建一个端到端模型,处理某一任务。
如果上述两个智能体足够智能不断进化达到一个较高的智能水平,那么我们今天提到的自动数据增强(AutoAugment)也许是原始雏形。
虽然David认为模型本身就应该含有大量的信息不应该是外部“强加”给模型大量信息(人类的基因不正是这样?)。同时Google利用大量的机器、实验和工作发的这篇论文普通AI从业者想复制比较困难,但有几点有意思的地方David想指出一下,
1. 虽然自动数据增强的训练模型较难重现,但是google已经公布用于检测的自动数据增强方法,其代码我们可以直接拿来用:https://github.com/tensorflow/tpu/blob/master/models/official/detection/utils/autoaugment_utils.py
并且提供了不只一种增强数据策略,如下只是其中一种策略:
def policy_v1():
"""Autoaugment policy that was used in AutoAugment Detection Paper."""
# Each tuple is an augmentation operation of the form
# (operation, probability, magnitude). Each element in policy is a
# sub-policy that will be applied sequentially on the image.
policy = [
[('TranslateX_BBox', 0.6, 4), ('Equalize', 0.8, 10)],
[('TranslateY_Only_BBoxes', 0.2, 2), ('Cutout', 0.8, 8)],
[('Sharpness', 0.0, 8), ('ShearX_BBox', 0.4, 0)],
[('ShearY_BBox', 1.0, 2), ('TranslateY_Only_BBoxes', 0.6, 6)],
[('Rotate_BBox', 0.6, 10), ('Color', 1.0, 6)],
[('Color', 0.0, 0), ('ShearX_Only_BBoxes', 0.8, 4)],
[('ShearY_Only_BBoxes', 0.8, 2), ('Flip_Only_BBoxes', 0.0, 10)],
[('Equalize', 0.6, 10), ('TranslateX_BBox', 0.2, 2)],
[('Color', 1.0, 10), ('TranslateY_Only_BBoxes', 0.4, 6)],
[('Rotate_BBox', 0.8, 10), ('Contrast', 0.0, 10)],
[('Cutout', 0.2, 2), ('Brightness', 0.8, 10)],
[('Color', 1.0, 6), ('Equalize', 1.0, 2)],
[('Cutout_Only_BBoxes', 0.4, 6), ('TranslateY_Only_BBoxes', 0.8, 2)],
[('Color', 0.2, 8), ('Rotate_BBox', 0.8, 10)],
[('Sharpness', 0.4, 4), ('TranslateY_Only_BBoxes', 0.0, 4)],
[('Sharpness', 1.0, 4), ('SolarizeAdd', 0.4, 4)],
[('Rotate_BBox', 1.0, 8), ('Sharpness', 0.2, 8)],
[('ShearY_BBox', 0.6, 10), ('Equalize_Only_BBoxes', 0.6, 8)],
[('ShearX_BBox', 0.2, 6), ('TranslateY_Only_BBoxes', 0.2, 10)],
[('SolarizeAdd', 0.6, 8), ('Brightness', 0.8, 10)],
]
return policy
2. 强化学习和GAN哪个更好? 继续阅读CVPR2019观察: 谷歌大脑的”自动数据增强”方法及其前景,David9划重点

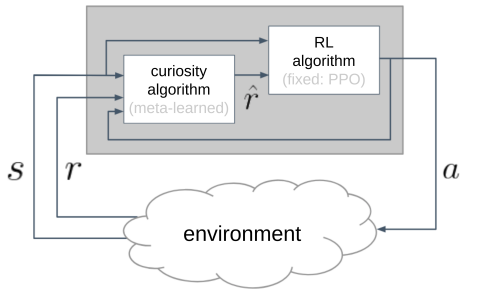
 是RL算法真正训练使用的回报。(并不直接使用环境回报r )。
是RL算法真正训练使用的回报。(并不直接使用环境回报r )。